
9398 IEEE JOURNAL OF SELECTED TOPICS IN APPLIED EARTH OBSERVATIONS AND REMOTE SENSING, VOL. 15, 2022
CNN-Based Large Area Pixel-Resolution
Topography Retrieval From Single-View LROC
NAC Images Constrained With SLDEM
Hao Chen ,XuanyuHu , Philipp Gläser , Haifeng Xiao ,ZhenYe , Hanyue Zhang,
Xiaohua Tong , Senior Member, IEEE, and Jürgen Oberst
Abstract—The production of high-resolution digital terrain
models (DTMs) based on images is often hampered by the lack of
appropriate stereo observations. Here, we propose a deep learning-
based reconstruction of pixel-resolution DTMs from Lunar Recon-
naissance Orbiter (LRO) single-view narrow angle camera (NAC)
images, constrained by Selenological and Engineering Explorer
and LRO LOLA Elevation Models (SLDEM). The procedure is
carried out for a set of adjacent images, and the mosaicking of
a contiguous large-area DTM is demonstrated. The approach is
applied to the CE-3 and CE-4 landing sites, involving six multiple
coverage and eight adjacent NAC L/R image pairs, respectively. For
the DTM reconstruction, we use an improved convolutional neural
network architecture with a weighted sum loss function involving
three loss terms. We demonstrate that our method is robust and can
deal with images acquired under varying illumination conditions.
The DTM mosaic (1.5 m pixel size) covering the CE-4 landing area
(72.8 ×30.3 km) is without apparent seams between the individual
image boundaries and consistent with the SLDEM (60 m pixel
size) in terms of overall elevation, trend, and scale, but is showing
considerably more morphologic detail.
Manuscript received 29 June 2022; revised 14 September 2022; accepted 1
October 2022. Date of publication 17 October 2022; date of current version 9
November 2022. The work of Hao Chen was supported by the China Scholarship
Council (CSC) for his Ph.D. study at Technische Universität Berlin, Berlin,
Germany. This work was supported in part by the National Natural Science
Foundation of China under Grant 42101447, in part by the Shanghai Sailing
Program under Grant 21YF1448800, and in part by the Open Access Publication
Fund of TU Berlin. (Corresponding authors: Xuanyu Hu; Zhen Ye.)
Hao Chen is with the Institute of Geodesy and Geoinformation Science,
Technische Universität Berlin, 10553 Berlin, Germany, also with the College
of Surveying and Geo-Informatics, Tongji University, Shanghai 200092, China,
and also with the Shanghai Key Laboratory of Space Mapping and Remote Sens-
ing for Planetary Exploration, Shanghai 200092, China (e-mail: hao.chen.2@
campus.tu-berlin.de).
Xuanyu Hu, Philipp Gläser, and Haifeng Xiao are with the Institute of Geodesy
and Geoinformation Science, Technische Universität Berlin, 10553 Berlin,
Zhen Ye is with the College of Surveying and Geo-Informatics, Tongji
University, Shanghai 200092, China, and also with the Shanghai Key Laboratory
of Space Mapping and Remote Sensing for Planetary Exploration, Shanghai
Hanyue Zhang is with the Precision Forestry Key Laboratory of Beijing,
Beijing Forestry University, Beijing 100083, China (e-mail: zhanghanyue@
bjfu.edu.cn).
Xiaohua Tong is with the College of Surveying and Geo-Informatics, Tongji
Jürgen Oberst is with the Institute of Geodesy and Geoinformation Science,
Technische Universität Berlin, 10553 Berlin, Germany, and also with the In-
stitute of Planetary Research, German Aerospace Center (DLR), 12489 Berlin,
Digital Object Identifier 10.1109/JSTARS.2022.3214926
Index Terms—Deep learning-based reconstruction, digital
terrain model (DTM) mosaics, pixel-resolution DTM, single-view
narrow angle camera (NAC) images, Selenological and Engineering
Explorer and LRO LOLA Elevation Model (SLDEM).
I. INTRODUCTION
DIGITAL terrain models (DTMs) play a ubiquitous role in
planetary exploration, e.g., in support of mission planning
[1], landing site selection [2], and autonomous landing and
hazard avoidance [3]. Terrain models are also prerequisite for
the investigation of planetary (sub-)surface environment, such as
illumination conditions [4], material properties [5], and volatile
distribution [6], and thus lay the groundwork for achieving
key scientific objectives. Most recent and future manned or
unmanned missions to the Moon will focus on lander, rover,
and sample return exploration [2], [7], [8]. To ensure a safe
and successful landing, DTMs are used to investigate terrain
slope, illumination conditions, Earth communication, and obsta-
cles (i.e., craters and rocks) distribution for the large candidate
landing areas to select suitable landing sites [9]. Currently, the
landing site selection work is mainly based on coarse-resolution
DTMs derived from laser altimetry measurements and stereo
photogrammetric models, e.g., 20 m resolution (CE-3 landing
area) and 30 m resolution (CE-4 landing area) DTMs derived
from the integration processing of Lunar Orbiter Laser Altimeter
(LOLA) measurements and CE-2 stereo imagery collected dur-
ing the circular orbit [10], [11]. Nevertheless, high resolution,
i.e., meter-scale or lander/rover footprint scale, DTMs display-
ing more refined landing area environment provides a more
detailed and faithful context for operations and investigations.
On the other hand, 1.5-m resolution digital orthophoto maps
(DOMs) were produced for the landing areas of CE-4 and CE-5
missions to extract craters and rocks that pose a safety hazard
for the lander [11], [12]. Due to the lack of the same resolution
topographic modeling to provide 3-D spatial information, some
works only used the distribution of obstacles to guide landing
site selection [11]. Actually, the volume of craters and rocks,
especially ones on a meter scale or larger, which needs to be
calculated from high-resolution DTMs, is also an important
criterion for the evaluation of landing safety [10], [13], [14].
Overall, it is highly desirable to develop effective new techniques
for large-area high-resolution lunar surface DTM generation,
This work is licensed under a Creative Commons Attribution 4.0 License. For more information, see https://creativecommons.org/licenses/by/4.0/

CHEN et al.: CNN-BASED LARGE AREA PIXEL-RESOLUTION TOPOGRAPHY RETRIEVAL 9399
which generally requires several adjacent high-resolution orbiter
images to cover.
The two narrow angle cameras (NACs), designated as NAC-
left (NAC-L) and NAC-right (NAC-R), onboard the Lunar Re-
connaissance Orbiter (LRO), operated in push-broom mode,
have collected a huge number of images with an unprecedented
pixel resolution up to 0.5 m, which are the primary data source
for high-resolution lunar surface 3-D reconstruction [15]. At the
nominal orbit height of 50 km, the two NACs cover a surface area
of 5–25 km [16]. Large areas, such as the landing areas of China’s
Lunar Exploration Program, usually require multiple adjacent
NAC images for complete coverage. Stereo-model-based pho-
togrammetry is the most widely used technique to retrieve high-
resolution lunar surface DTMs from stereo or multiview NAC
observations [15], [17]. While NACs have collected enough
measurements to almost completely cover the lunar surface at
least once, stereo pairs suitable for retrieving terrain models
(which require a tilting of the spacecraft in consecutive orbits)
are still spatially limited [17], [18]. Therefore, the construction
of large-area DTMs from multiple stereo NAC images has been
a long-standing challenge and issue. For example, even though
the single-view NAC images cover the whole CE-4 landing area
with approximately 72.8 ×30.3 km (177.6 °E ±1.2°, 45.5 °S
±0.5°), there is only one stereo pair of NAC images covering
a small portion of this area that could be used to generate a
photogrammetric DTM [11]. Most existing photogrammetric
DTMs are also only derived from a single stereo pair [15]. On
the other hand, shape from shading (SFS) methods, constrained
by coarse-resolution DTMs, have been successfully applied for
the fine-scale topographic retrieval of local lunar surface from
single NAC images [19], [20]; for example, the landing site of
CE-4 [11]. Nevertheless, SFS is time-consuming in the case
of large-scale mapping [21], and it is often to be less accurate
in the cross-sun direction [22]. In addition, the results of the
aforementioned techniques are often sensitive to image quality
and model parameterization in practice. Consequently, the qual-
ity control of the DTM demands substantial empirical expertise
and experience on an ad hoc basis [21], [23]. This, to a certain
extent, also limits the applicability of the photogrammetric and
SFS techniques to large-area DTM generation.
Nowadays, convolutional neural network (CNN)-based deep
learning methods have been applied to DTM generation from
single-view orbiter imagery for the lunar and Martian surfaces
[23], [24], [25]. Chen et al. [24] applied CNN-based deep learn-
ing method to Martian surface 3-D reconstruction from single
orbiter images. Their proposed network consists of two cas-
caded subnetworks. The first subnetwork is designed to convert
input images to Lambertian images, and the second to predict
DTMs from the Lambertian images. Tao et al. [23] developed a
single-image-input Martian surface 3-D reconstruction system
and produced three mapping products over the large activity area
of the planned ExoMars 2022 Rosalind Franklin rover mission.
Chen et al. [25] used the altimetric DTMs as part of the model
input to constrain model learning. They proposed a dual-branch
CNN architecture to predict pixel-resolution DTMs for the lunar
surface, with one branch devised specifically to process the
coarse-resolution DTM alongside single high-resolution images
as input. This way, the elevation constraint has been intrinsically
assimilated in the learning process, which was demonstrated to
significantly enhance the accuracy of model prediction. Further-
more, the deep learning methods can predict DTMs in a fast
and user-friendly way without a priori and expert knowledge
[23], and therefore may have great potential for large-area high-
resolution lunar topographic modeling.
In this article, we propose a deep learning-based reconstruc-
tion for large-area pixel-resolution lunar surface DTMs from
single-view NAC L/R image pairs and the Selenological and
Engineering Explorer and LRO LOLA Elevation Model (SL-
DEM). This is in contrast with photogrammetric technique,
which requires stereo or multiview overlapping images as input
to derive DTMs. Specifically, we introduce an improved CNN
architecture with a weighted sum loss function accounting for
three types of errors, which yield more accurate DTMs than
in our earlier efforts [25]. The input data are first coregistered
and splitted into small tiles in normalized scale. Once trained,
our method reconstructs DTMs from each tiles, and then, scale
recovery and mosaicking of DTM tiles inner and inter adjacent
image pairs are carried out.
Here, we present two model applications for the purpose of
validation as well as illustration. In the first case, we process six
NAC image L/R pairs, all of which provide a reasonable, and
thus repeated, coverage of the CE-3 landing site. This allows
us to rigorously verify the consistency of the reconstructed
DTMs under varying illumination conditions. In another, more
challenging application, the tested model is applied to the much
wider, whole landing area of CE-4. The full coverage of the
region requires multiple adjacent observations with partial or
even marginal overlap. We present the output DTM of 1.5 m
resolution of the CE-4 landing area based on eight neighboring
NAC pairs, which demonstrates not only the performance of
the proposed approach but also its imminent practicality for
large-area application.
The rest of this article is organized as follows. In Section II, we
present in detail our reconstruction pipeline and improved deep
learning network for large-area pixel-resolution lunar surface
DTM generation. In Section III, the experimental results and
analyses are provided to exhibit the capability of the presented
method. Finally, Section IV concludes this article.
II. DEEP LEARNING-BASED LARGE-AREA LUNAR SURFACE
RECONSTRUCTION
A. Reconstruction Pipeline
The entire reconstruction pipeline based on our improved
CNN architecture to retrieve the lunar surface large-area pixel-
resolution DTM is shown in Fig. 1. First, data preprocessing
is performed on NAC images and SLDEM to eliminate the
geometric inconsistency between them, and clipped into small
normalized tiles to meet the input requirements of our deep
learning network. Then, we use the well-trained model of our
proposed CNN architecture to estimate the DTMs from the input
tiles. The CNN architecture and model training are the core of
this work, which will be introduced in Section II-B. Finally, we
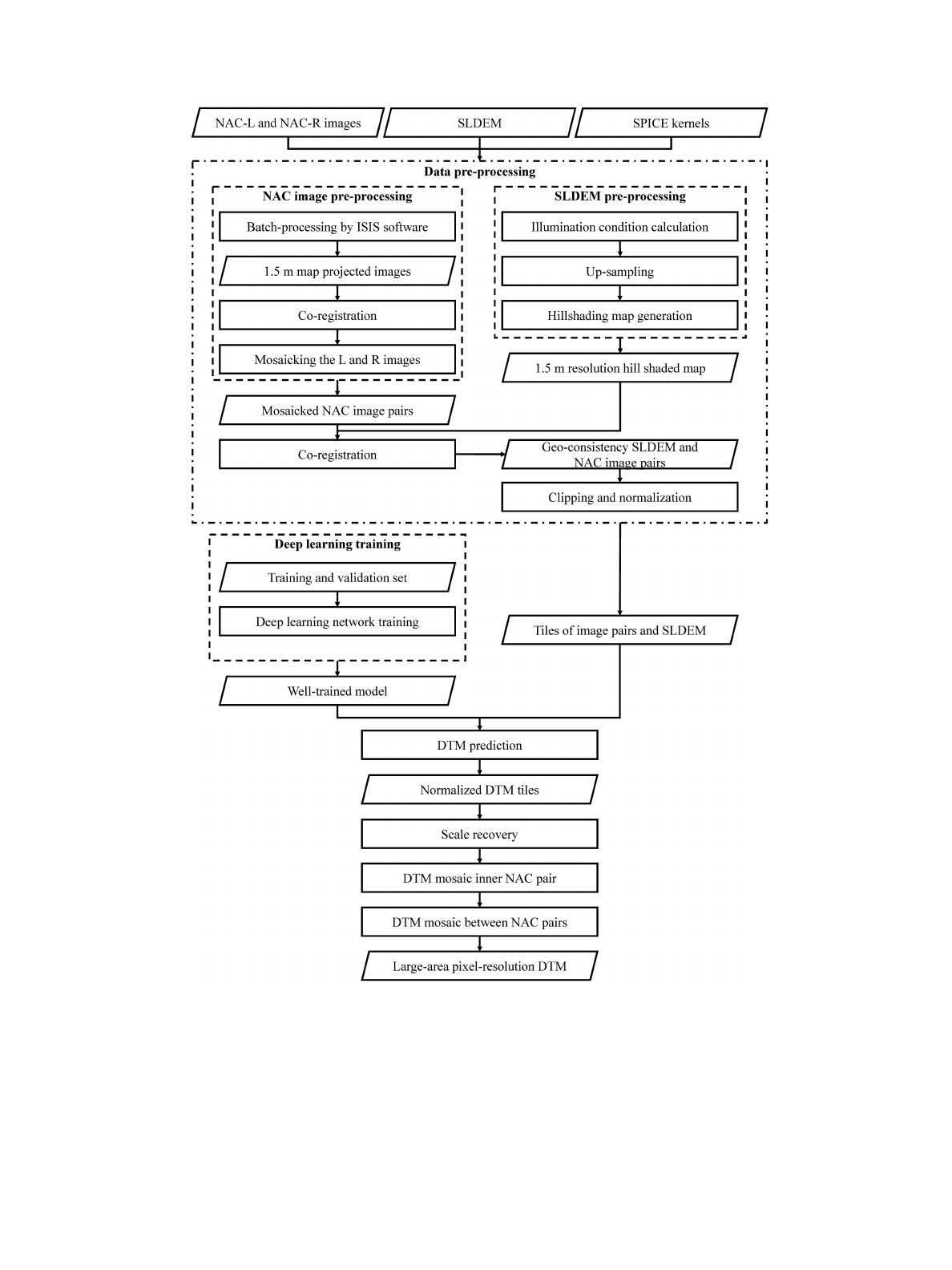
9400 IEEE JOURNAL OF SELECTED TOPICS IN APPLIED EARTH OBSERVATIONS AND REMOTE SENSING, VOL. 15, 2022
Fig. 1. Entire reconstruction pipeline for the large-area pixel-resolution DTM from NAC images and SLDEM.
recover the predicted, normalized DTM tiles to the real scale,
which are subsequently mosaicked to large areas.
1) Data Preprocessing: The reconstruction pipeline needs
only single-view high-resolution images and corresponding
coarse-resolution DTMs as input to derive pixel-resolution
DTMs, i.e., with the same ground sample distance of input
images. The NAC images feature the highest resolution of orbiter
images available and offer almost complete coverage of the lunar
surface in single view [12]. The NAC-L and NAC-R images are
acquired simultaneously with ∼135 pixels overlapping in the
cross-track direction of the LRO orbit [14]. As our approach
requires no prior knowledge of camera models, observations
through the two lenses with independent camera models can be
mosaicked together directly to increase the swath coverage. The
NAC images used for DTM reconstruction in this article are
all the mosaicked images from NAC-L and NAC-R (hereafter

CHEN et al.: CNN-BASED LARGE AREA PIXEL-RESOLUTION TOPOGRAPHY RETRIEVAL 9401
designated as “NAC image pairs”). On the other hand, the
SLDEM is a combined product of LOLA measurements and
photogrammetric models derived from SELENE terrain camera
images covering latitudes within ±60° [26].1While it has a
relatively low spatial resolution of 60 m, the SLDEM is more
accurate and suffers from fewer artifacts than the LOLA DTM
[26]. We select it as the input coarse-resolution DTM.
The NAC experimental data record images can be downloaded
from NASA’s Planetary Data System and batch processed by
Integrated System for Imagers and Spectrometers software to
attach the SPICE kernels (spiceinit tool) [27], perform radiomet-
ric corrections (lronaccal tool), remove echo effects (lronacecho
tool), and obtain the map-projected products with 1.5 m resolu-
tion (cam2map tool).
An affine transformation model [28], displayed in the fol-
lowing, is used to coregister the images to remove geometric
discrepancies between the NAC observations in both intra and
intertrack cases as well as the SLDEM:
rr=a0+a1cs+a2rs
cr=b0+b1cs+b2rs(1)
where (rr,cr) is the geographic location of the reference image,
(rs,cs) is the geographic location of the source image, a0,a1,
a2,b0,b1, and b2are affine transformation parameters, which
are calculated from the tie points between the reference and
source images. The SLDEM is the reference for the whole
coregistration process. The NAC-L images are the reference for
the NAC-R images. First, all the NAC-R images are coregistered
to their NAC-L counterparts before mosaicking to NAC image
pairs. The NAC images and SLDEM have a large difference in
resolution and represent different modalities of surface, which
makes it difficult to coregister them directly. To overcome this
issue, the SLDEM is resampled to match the resolution of the
NAC images. Based on the upsampled SLDEM, a simulated
image is generated using hill shading techniques [29] to re-
sembling the illumination conditions at the times of the NAC
image acquisition. The NAC image pair in the central part of the
whole area is first registered to the simulated image of SLDEM
and then used as the reference for the neighboring images.
Then, the new registered image pair becomes new reference for
subsequent adjacent pairs until all are registered. If the overlap
between the registered image and the neighboring image is large
enough, the registered image will become the new reference
for ensuing registration with the adjacent image; otherwise,
the image simulated with SLDEM is used as a complementary
reference.
The size of the input data for the deep learning network is
dependent on the model architecture and constrained by machine
memory. The present study uses a single Nvidia RTX3060
graphic card with a 12 GB memory. The NAC image pairs and
corresponding SLDEMs are clipped into small overlapping tiles
(256 ×320 pixels per tile, with 100 overlapping pixels in the
horizontal and vertical directions). We normalize the gray values
of the image tiles to [0, 1] [see (2)], and accordingly, the heights
1Downloaded from http://imbrium.mit.edu/EXTRAS/SLDEM2015/
of SLDEM tiles to standard normal distribution, and subtract
the minimum value for each normalized SLDEM tiles [see (3)]
to ensure that the distribution of our input is consistent with the
dataset used to training the deep learning model
ˆ
I=(I−min (I)) /(max (I)−min (I)) (2)
ˆ
D=(D−μ)/σ −min ((D−μ)/σ)(3)
where Iand ˆ
Irepresent the original and normalized images,
respectively, Dand ˆ
Drepresent the original and normalized
SLDEMs, respectively, and μand σrepresent the mean and
standard deviation of the original SLDEM heights.
2) Construction of Large-Area Pixel-Resolution DTM: The
preprocessed small tiles of NAC image pairs and SLDEM are
input to the well-trained model of our improved CNN archi-
tecture (see Section II-B for detailed description) to predict the
pixel-resolution DTM tiles. The DTM tiles are in normalized
scale with small size. After DTM prediction, the scale recovery
and DTM mosaicking are carried out to construct the large-area
DTM.
First, we use the mean and standard deviation value of ref-
erence SLDEM elevations to recover the initial scale of the
normalized predicted DTMs
DTMinit_scale =σ∗DTMnorm_scale +μ(4)
where DTMinit_scale is the initial recovered DTM, and
DTMnorm_scale is the predicted DTM in normalized scale.
In (3), we add a bias to ensure that the heights of normalized
SLDEM are all greater than or equal to 0, the initial recovered
DTM is missing this bias. Besides, the pixel-resolution pre-
dicted DTMs derived from the network contain abundant high-
frequency elevation details. In contrast, the coarse-resolution
reference only provides low-frequency information. As a result,
there are still varying degrees of vertical deviation between
initial recovered DTMs and the reference. We use the pc_align
tool in Ames Stereo Pipeline (ASP) to align the initial recovered
DTMs to SLDEM in order to make the elevation between
adjacent tiles consistent [30].
Then, we adopt the dem_mosaic tool in ASP to mosaic the
DTM tiles to large area. First, we mosaic the DTM tiles from
inner NAC pairs to derive DTM mosaics for the individual NAC
image pairs. Then, we mosaic the DTM mosaics of adjacent
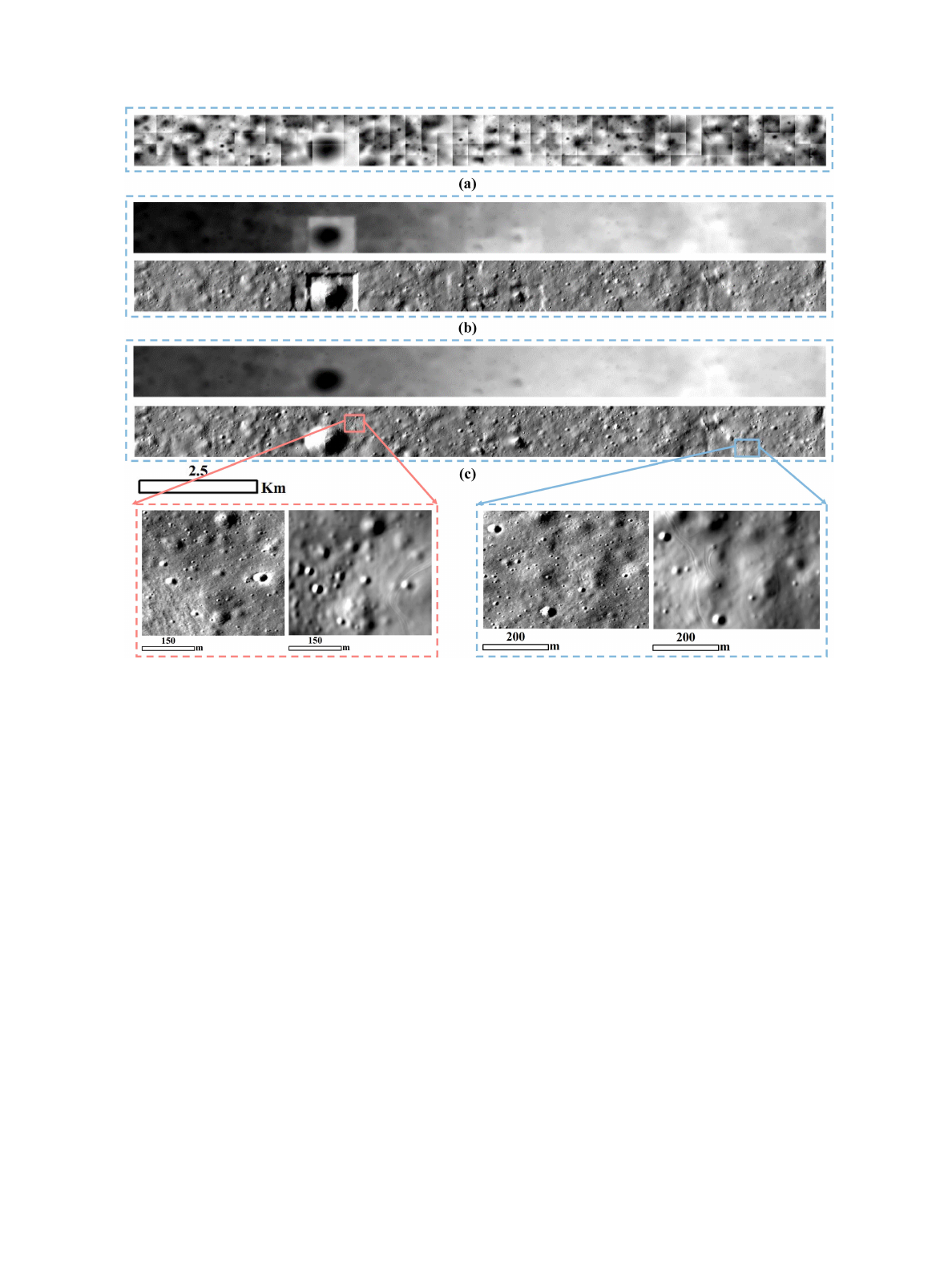
NAC pairs to derive the whole large-area DTM mosaic. Fig. 2
shows that the pc_align step can effectively suppress artifacts
caused by vertical disparities between neighboring DTM tiles.
The DTM prediction, scale recovery, and DTM mosaicking can
be implemented simultaneously between different NAC image
pairs.
B. Deep Learning Method for DTM Reconstruction
1) Improved Network Architecture: As the high-resolution
orbiter imagery and coarse-resolution DTM characterize differ-
ent modalities of the lunar surface, Chen et al. [25] proposed a
dual-branch CNN architecture with a weighted sum loss function
consisting of two loss terms to estimate pixel-resolution DTMs
9402 IEEE JOURNAL OF SELECTED TOPICS IN APPLIED EARTH OBSERVATIONS AND REMOTE SENSING, VOL. 15, 2022
Fig. 2. Example of DTM mosaic. (a) Initial recovered DTM tiles. (b) DTM mosaic and the derived hill shaded map without applying pc_align. (c) DTM mosaic
and the derived hill shaded map after applying pc_align. The bottom panels present the zoom-in views of original NAC images and the hill shaded maps after
applying pc_align in two local areas.
from single-view images and coarse-resolution DTMs. In its net-
work, two independent encoder branches, high-resolution image
encoder branch (HIEB) and coarse-resolution DTM encoder
branch (CDEB), were established. As the input images feature
fine texture details, the HIEB is built based on the ResNet50
architecture [31], which has been broadly employed in deep
learning-based depth estimation from high-resolution single
images to extract abundant textural features [32]. By contrast,
the CDEB is built with five stacked simple convolution blocks to
extract the vertical features from input DTMs. The outputs from
the encoder branches are merged before being processed by the
decoder module, in which five stacked upsampling blocks are
designed in order to restore the resolution of the predicted DTM
at the same level as the input. The first four are upprojection
blocks [33], and the last one is simple nearest upsampling block
[25]. At the same time, in order to take the full advantage of
multiscale terrain features extracted from the HIEB to assist in
predicting DTMs with finer terrain details, the input for the last
four blocks of decoder module is concatenated by the output
from the previous block and the counterpart in the HIEB with
the same spatial resolution. The final step includes a convolu-
tion layer and a rectified linear unit activation function [34] to
produce a single-channel output, which will be the predicted
DTM.
Compared with networks with image-only input or single-
branch architecture with coarse-resolution DTM as constraint,
the method of Chen et al. [25] provides a higher elevation
accuracy and sensitivity to terrain details. However, when it
comes to ultradetails, e.g., extremely small-scale craters with
a few pixels, the model capability is still limited and may
suffer from the occurrence of perceptible noises in certain areas.
This article aims at two objectives: 1) the first convolution
layer of the HIEB in [25] contains more specific texture fea-
tures than the layers that follow. The output of this layer is
directly connected to the last block of the decoder module to
enable the model to predict more small-scale terrain details.
Here, we reduce the convolution kernel of this layer from
7×7pixelsto3×3 pixels to enable the model to extract
more local details. 2) The deconvolution layers in upprojection
blocks for spatial upsampling is prone to generating excessive
noise [24], [35]. Here, we adopt the nearest neighbor inter-
polation algorithm instead of the deconvolution operation for
spatial upsampling. The improved network architecture is shown
in Fig. 3.
Loading more pages...