
Received: 25 August 2021 Revised: 21 October 2021 Accepted: 14 November 2021
DOI: 10.1002/spe.3058
RESEARCH ARTICLE
AuctionWhisk: Using an auction-inspired approach for
function placement in serverless fog platforms
David Bermbach1Jonathan Bader2Jonathan Hasenburg1
Tobias Pfandzelter1Lauritz Thamsen2
1Mobile Cloud Computing Research
Group, TU Berlin & Einstein Center
Digital Future, Berlin, Germany
2Distributed and Operating Systems
Research Group, TU Berlin, Berlin,
Germany
Correspondence
David Bermbach, TU Berlin, Sekr. EN17,
Einsteinufer 17, D-10587 Berlin, Germany.
Email: [email protected]
Abstract
The Function-as-a-Service (FaaS) paradigm has a lot of potential as a com-
puting model for fog environments comprising both cloud and edge nodes,
as compute requests can be scheduled across the entire fog continuum in
a fine-grained manner. When the request rate exceeds capacity limits at the
resource-constrained edge, some functions need to be offloaded toward the
cloud. In this article, we present an auction-inspired approach in which applica-
tion developers bid on resources while fog nodes decide locally which functions
to execute and which to offload in order to maximize revenue. Unlike many cur-
rent approaches to function placement in the fog, our approach can work in an
online and decentralized manner. We also present our proof-of-concept proto-
type AuctionWhisk that illustrates how such an approach can be implemented
in a real FaaS platform. Through a number of simulation runs and system exper-
iments, we show that revenue for overloaded nodes can be maximized without
dropping function requests.
KEYWORDS
distributed scheduling, fog computing, function-as-a-service, serverless computing
1INTRODUCTION
Recently, the paradigm of fog computing has received more and more attention. In fog computing, cloud resources are
combined with resources at the edge, that is, near the end user or close to IoT devices, and in some cases also with
additional resources in the network between cloud and edge.1While this adds complexity for applications, it comes with
three key benefits: First, leveraging compute resources at or near the edge can lower response times, which is crucial for
application domains such as autonomous driving or 5G mobile networks.1,2 Second, data can be filtered and preprocessed
early on the path from edge to the cloud, which reduces the data volume.3Especially in IoT use cases, it is often not
feasible to transmit all data to the cloud as the sheer volume of produced data exceeds the bandwidth capabilities of the
network4or leads to significant energy consumption for wide-area networking.5Third, keeping parts of applications and
data at the edge can help to improve privacy, for example, by avoiding “centralized data lakes”6in the cloud. Overall, fog
computing, thus, combines the benefits of both cloud and edge computing.
This is an open access article under the terms of the Creative Commons Attribution-NonCommercial License, which permits use, distribution and reproduction in any
medium, provided the original work is properly cited and is not used for commercial purposes.
© 2021 The Authors. Software: Practice and Experience published by John Wiley & Sons Ltd.
Softw: Pract Exper. 2022;52:1143–1169. wileyonlinelibrary.com/journal/spe 1143

1144 BERMBACH et al.
While there are many open research questions in fog computing, a key question has not been answered yet: Which
compute paradigms will future fog applications follow? In previous work,1we argued that a serverless approach—which
we understand as Function-as-a-Service (FaaS) in this article—is a good fit for the edge. The main reason for this is that
resources at the edge are regularly considerably constrained so that provisioning them in small function slices is more
efficient than provisioning them using virtual machines or long-running containers. Additionally, the idea of having
strictly stateless functions, separated from data management,7,8 supports moving parts of applications seamlessly between
edge and cloud resources.
Now, assuming a serverless world in which application components can run as functions on FaaS platforms in the
cloud, at the edge, and medium-sized data centers in between, the question of how to distribute fog application com-
ponents can be reduced to the issue of function placement across multiple geo-distributed sites. In Reference 9, we
introduced the idea of using auction-inspired mechanisms for function placement and evaluated it in small-scale simu-
lation experiments. We were able to confirm our assumptions that this would be an efficient approach to decentralized
scheduling of functions over a distributed fog infrastructure and have argued for further work in this area. In this article,
we extend our previous work and make the following contributions:
1. We describe a more general conceptual approach of using a decentralized auction scheme to control function
placement (Section 3).
2. We discuss practical engineering challenges for implementing this approach in existing FaaS platforms (Section 4)
3. We present a simulation tool as well as the underlying system model and use it to study the effects of various parameters
on our auction-based function placement (Section 5).
4. We implement our approach as a proof-of-concept prototype called AuctionWhisk based on Apache OpenWhisk and
evaluate our prototype through experiments (Section 6).
5. We critically discuss the limitations of our work and identify future research directions in the field (Section 7).
2BACKGROUND
In this section, we introduce and describe fundamental concepts of FaaS, fog computing, and auctions. As all three topics
have received major attention in research in the last few years and different definitions have emerged, we want to clarify
the terminology we adopt in this article. We also give a short overview of Apache OpenWhisk which we used as basis for
our prototype system.
2.1 Function-as-a-Service (FaaS)
Within the field of cloud computing, the Function-as-a-Service (FaaS) paradigm has emerged as the latest evolution in
resource sharing. The FaaS programming model facilitates highly scalable event-driven applications.
Developers deploy their code in the form of functions to a FaaS platform that handles code invocation and
scaling, lowering the management burden for the consumer. Here, a function is a piece of business logic that is
executed in response to an event. Functions can be implemented in any programming language as long as a run-
time environment for the language is supported by the target FaaS platform. Events can be web requests, monitoring
data, or even IoT sensor readings, thus making the FaaS approach a versatile option for many use cases. Logi-
cally, these functions live only as long as they process a single event and are reset with every invocation. This is
usually achieved with lightweight virtualization techniques such as containerization, microVMs, or unikernels,10-12
which enable FaaS platforms to spin up and destroy isolated instances quickly. As a result, no state can be per-
sisted within a function across multiple invocations, they are thus referred to as “stateless”. This is also one of the
main reasons for their scalability: A FaaS platform can spin up multiple concurrent instances of a function to handle
concurrent events, while quickly shutting them down to free up resources for other functions. The same character-
istic makes FaaS functions a good fit to fog and edge environments:1When migrating functions, there is no need
to handle session state within the function container. Instead, the function container can simply be terminated on
the original node and restarted on the new node. In practice, FaaS functions are usually used in conjunction with
other platform services, especially in combination with storage and database services that manage state, for example
Reference 13.
BERMBACH et al. 1145
Target NamespaceExternal Service
Feed
Event
Source
Action Output
Trigger
Rule
FIGURE 1 The OpenWhisk programming model18
nginx
CouchDB
KafkaController
Invoker
Invoker
Invoker
Docker
…
Client
Client
Client
OpenWhisk
FIGURE 2 Components of an OpenWhisk deployment18
While scalability and low management overhead are clear advantages for developers, operators have the benefit that
their infrastructure can be leveraged more efficiently. Instead of allocating coarsely grained resources in the form of virtual
machines or containers statically, these more finely grained functions can be more efficiently mapped to underlying
infrastructure and moved dynamically.14-16 The platform provider can then charge tenants based on actual usage. In 2021,
all major cloud service providers offer such a FaaS platform, for example, AWS Lambda*, Microsoft Azure Functions†,
Google Cloud Functions‡, or IBM Cloud Functions§.
2.2 Apache OpenWhisk
In addition to cloud-hosted FaaS platforms, a number of options for FaaS platforms have also emerged in research and
open source communities, for example, tinyFaaS,10 OpenLambda,15 or SAND.17 Another noteworthy example is Apache
OpenWhisk, which is also at the core of IBM’s Cloud Function service.7
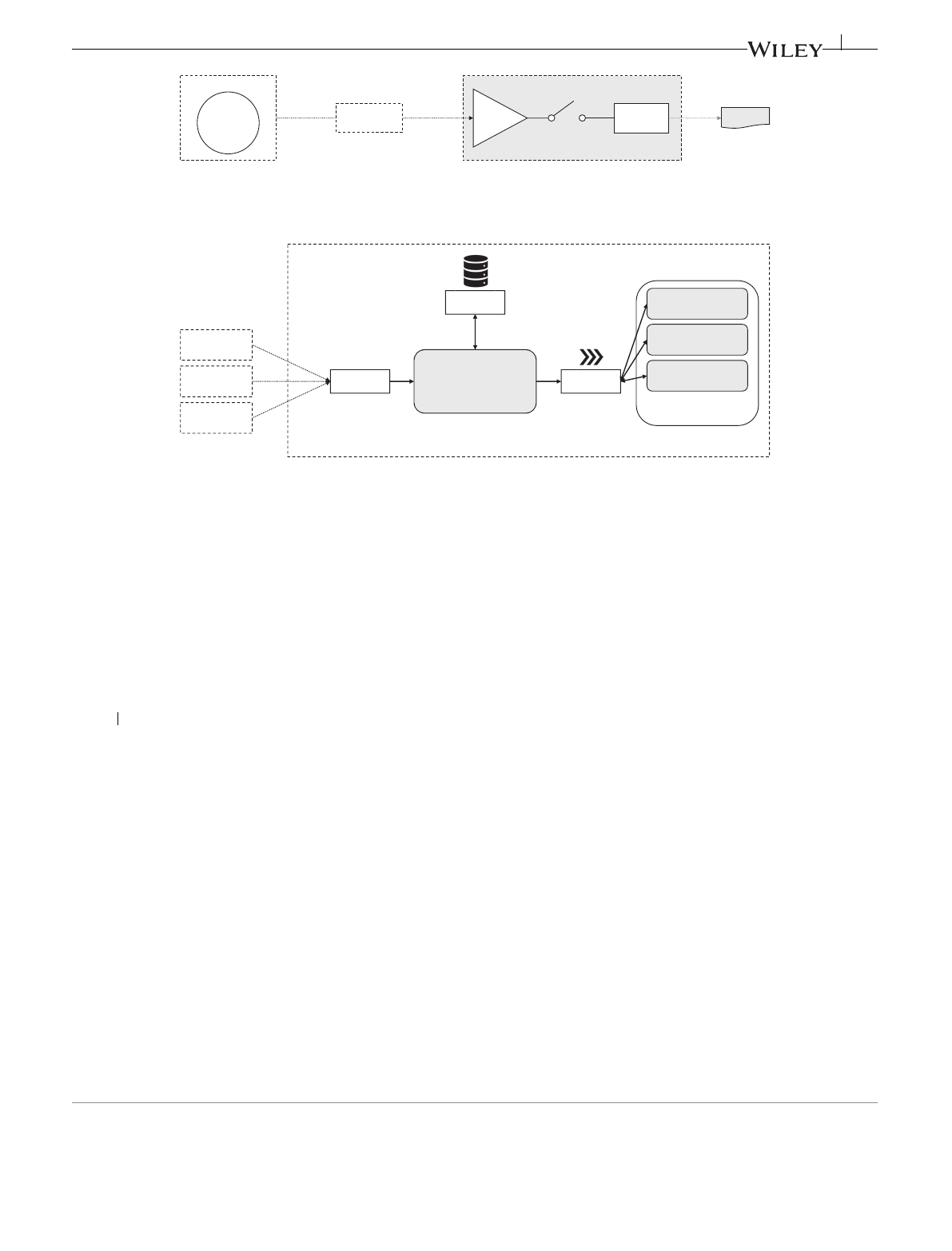
The OpenWhisk platform allows for custom functions, called actions, to be executed in response to an event, the trig-
ger. Figure 1 gives a high-level overview of the programming model as shown in the official OpenWhisk documentation.
Similarly, Figure 2 gives an overview of the OpenWhisk components: At the core of the OpenWhisk platform, the
Controller provides endpoints to process triggers and schedules action invocations. The Invokers use Docker containers
to isolate different actions, with a new container being spawned for each execution request. A Kafka queue serves as a
buffer between Controller and Invoker, for example, to avoid unnecessary cold starts.19 Additionally, a CouchDB instance
holds actions, triggers, rules, and user-related information such as credentials or namespaces; nginx is used as the HTTP
endpoint for the platform.
A complete installation of the OpenWhisk platform requires a substantial amount of resources which may not
always be available to the FaaS platform, especially when moving toward the edge. For this reason, there is also a more
lightweight version of OpenWhisk—Lean OpenWhisk. Lean OpenWhisk removes components such as the CouchDB
database and Kafka queue in order to leave more resources for the function instances at the cost of some platform
features.
*aws.amazon.com/lambda.
†azure.com/functions.
‡cloud.google.com/functions.
§www.ibm.com/cloud/functions.
1146 BERMBACH et al.
2.3 Fog computing
As the interest in fog computing increased, we have seen the emergence of different, often conflicting definitions of the
term. In some cases, it is used as a synonym for edge computing, in others it is used to refer to resources that sit between
edge and cloud or to all resources between cloud and device. In this article, we adopt the definition of Reference 1, where
fog resources encompass all resources in edge, cloud, and in between, yet not those of end devices. We refer to these
end devices also as “clients” and mean (embedded) IoT devices as well as mobile phones or computers, and to resources
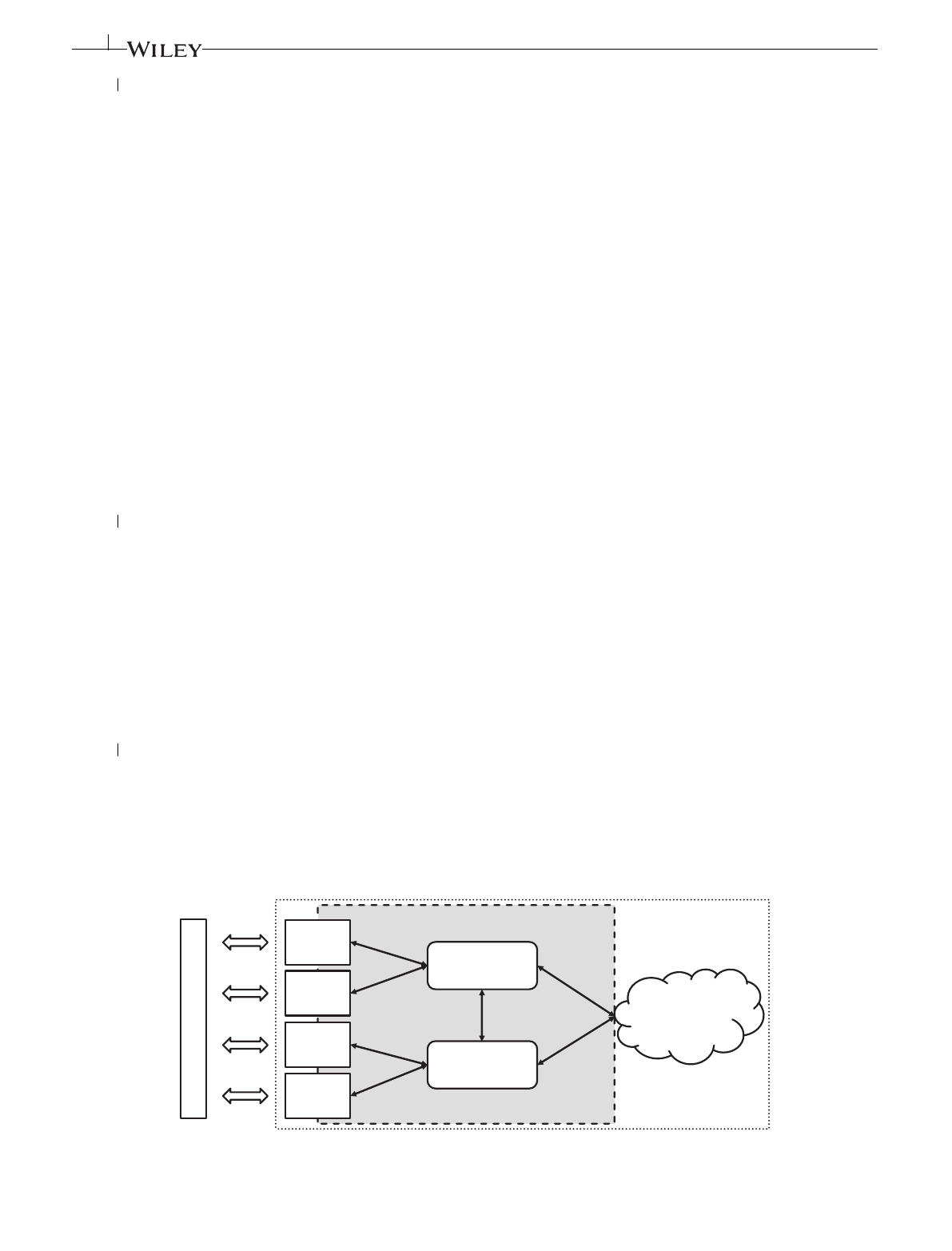
between edge and cloud as “intermediary nodes” or “intermediary” in short. We show an overview of cloud, edge, and
fog computing in Figure 3.
This definition yields transparency from a client perspective, as clients simply access fog resources unaware of whether
a particular service resides at the edge or in the cloud. Rather, they only see a singular “fog”.
In reality, the implementation of the fog is expected to follow a hierarchical model, where small edge nodes are collo-
cated with access network equipment such as radio towers and fewer yet larger intermediary nodes are placed within the
core network. Edge nodes will usually have the capabilities of single hosts such as Raspberry Pis or a small local cluster,
while intermediaries are small- to medium-sized data centers. At the root of the tree-like model is the cloud with its seem-
ingly infinite compute and storage resources. This leads to tradeoff decisions that have to be made for each application:
on the one end, edge nodes can provide low latency, high bandwidth resource access for client devices, albeit with less
available or more expensive resources. At the other end, the cloud provides scalable and (seemingly) infinite resources,
but at the cost of large network distances to clients. Intermediary fog nodes fall somewhere in between.
2.4 Fog-based FaaS platforms
We expect the paradigm of fog computing to enable entirely new classes of services and also to increase the
quality-of-service (QoS)20 of existing applications. In order to leverage the capabilities of the fog, it has been proposed to
deploy applications on FaaS platforms that run on the fog infrastructure.10,12,21-25
Open source platforms such as OpenWhisk or OpenLambda15 are a good fit for cloud nodes and larger intermediary
nodes, yet their larger deployment overheads make them unsuitable for smaller intermediaries or the edge.26 On more
constrained nodes, Lean OpenWhisk and tinyFaaS10 are possible options for function deployment, whereas NanoLambda
is an option for on-device FaaS deployment.22
2.5 Auctions
When demand for a product or service exceeds its available supply, auctions can be used to reach market equilibrium
(i.e., to match suppliers with the optimal buyers). In an auction, all potential buyers enter bids which ideally correspond
to the amount they are willing to pay. An auctioneer then sets auction rules which determine (i) how the winning bid(s)
are chosen and (ii) which price the successful buyers have to pay.
Fog
Cloud
Edge
Edge
Edge
Edge
Core Network
Intermediary
Intermediary
Client Devices
FIGURE 3 Overview of cloud, edge, and fog computing (adapted from Reference 1)

BERMBACH et al. 1147
There is a large body of research on different auction rules. Here, we focus on the so-called sealed-bid auctions in which
potential buyers enter their bids hidden from other potential buyers and the winner (or winners if there is more than one
auctioned item) of the auction is the buyer with the highest bid. In these sealed-bid auctions, there are two fundamental
rules for setting the price: in first-price auctions, the winner pays its bid; in second-price auctions, the winner pays the bid
of the second highest (unsuccessful) potential buyer. The latter strategy is recommended whenever it is important that
bids are truthful, that is, they correspond to the price that the potential buyers consider fair.
In the rest of this article, we will not expressly differentiate between different auction types but will implicitly assume
either a first-price or second-price sealed auction. In the approach that we will present, it does not matter which pricing
rule is used—they may affect prices but will not affect whether a placement decision is reached.
3AUCTION-BASED FUNCTION PLACEMENT
While a number of FaaS systems is already available, as discussed in Section 2.1, it is still not clear how to connect different
FaaS deployments. Ideally, we would want edge, intermediary, and cloud deployments to coordinate function placement
among each other. For instance, a request arriving in the cloud should probably still be processed in the cloud. A request
arriving at the edge, however, should in most cases (exceptions include functions that require data located elsewhere8)
be executed right at the edge. Only when the load on the edge node exceeds the available capacity should the request be
delegated to an intermediary (and likewise from intermediaries toward the cloud). This concept, similar to cloud bursting,
is based on the intuition of the cloud practically providing infinite resources.27
Based on this, we can conclude that function placement is straightforward when nodes have spare capacity (see also
Reference 12 for a more general discussion) but becomes challenging when, for instance, an edge node is overloaded.
In such a situation, the question is which request should be delegated to the next node on the path to the cloud as that
request will incur extra latency. For reasons of resilience and fault-tolerance in a geo-distributed fog environment, such
scheduling should ideally be managed in a decentralized manner, that is, through local decisions on each node. We can
imagine a number of objectives and criteria for such local decisions, for example, to prefer short-running functions over
long-running ones (and vice versa), to consider bandwidth impacts, to give some clients preference over others, or to
prefer latency-critical functions over less critical ones.
In contrast to these, we propose to use an auction-inspired approach, which has been shown to lead to an efficient
resource allocation in multiple domains (e.g., References 28-35): When application developers deploy their function
to an integrated fog FaaS platform, they also attach two bids to the executable. The first bid is the price that the
respective developer is willing to pay for a node to store the executable (in $/s), the second bid is for the actual exe-
cution of the function (in $/execution). In practice, both bids are likely to be vectors so that developers could indicate
their willingness to pay more on edge nodes than in the cloud or even on a specific edge node. We explicitly distin-
guish bids for storage of the executable and the execution as edge nodes might encounter storage limits independently
from processing limits. Both auctions closely resemble a sequence of first-price sealed-bid auctions as discussed in
Section 2.5.
For ease of explanation, we use a first-price auction, although a second-price auction would be preferable in practice.
Furthermore, as there is likely to be a minimum price equivalent to today’s cloud prices, we can consider both bids a
surcharge on top of a constant regular cloud price. For sake of clarity and since it has no impact on the bids, we leave this
constant price aside in our explanation.
Storage bids: The nodes in our approach—edge, intermediaries, and cloud—analyze these bids and can make a
local decision, that is, act as auctioneers, which is important for overall scalability and resiliency. We assume that cloud
nodes will accept all bids that exceed some minimum base price. All other nodes will check whether they can store
the executable. When there is enough remaining capacity, nodes simply store the executable together with the attached
bids and start charging the application based on the storage bid. When there is not enough disk space left, nodes decide
whether they want to reject the bid or remove another already stored executable. For this, nodes try to maximize their
earnings. A simple strategy for this, comparable to standard bin packing, is to order all executables by their storage bid
(either the absolute bid or the bid divided by the size of the executable) and remove stored executables until the new one
fits in. Of course, arbitrarily comprehensive strategies can be used (in Section 5.5, we will show through simulation how
changing this auctioning strategy affects results) and could even consider the processing bid and the expected number of
executions. In the end, this leads to a situation where some or all nodes will store the executable along with its bids. See
also Figure 4 for an overview of this auction step.
Loading more pages...