
foods
Review
Diving Deep into the Data: A Review of Deep Learning
Approaches and Potential Applications in Foodomics
Lisa-Carina Class 1,2,†, Gesine Kuhnen 1,3,† , Sascha Rohn 2,3 and Jürgen Kuballa 1,*
Citation: Class, L.-C.; Kuhnen, G.;
Rohn, S.; Kuballa, J. Diving Deep into
the Data: A Review of Deep Learning
Approaches and Potential
Applications in Foodomics. Foods
2021,10, 1803. https://doi.org/
10.3390/foods10081803
Academic Editors:
Domenico Montesano,
Gabriele Rocchetti,
Alessandra Bordoni and
Francesco Capozzi
Received: 29 June 2021
Accepted: 2 August 2021
Published: 4 August 2021
Publisher’s Note: MDPI stays neutral
with regard to jurisdictional claims in
published maps and institutional affil-
iations.
Copyright: © 2021 by the authors.
Licensee MDPI, Basel, Switzerland.
This article is an open access article
distributed under the terms and
conditions of the Creative Commons
Attribution (CC BY) license (https://
creativecommons.org/licenses/by/
4.0/).
1GALAB Laboratories GmbH, Am Schleusengraben 7, 21029 Hamburg, Germany;
2Hamburg School of Food Science, Institute of Food Chemistry, University of Hamburg, Grindelallee 117,
20146 Hamburg, Germany
3
Department of Food Chemistry and Analysis, Institute of Food Technology and Food Chemistry, Technische
*Correspondence: juer[email protected]
† Both authors contributed equally to this work.
Abstract:
Deep learning is a trending field in bioinformatics; so far, mostly known for image pro-
cessing and speech recognition, but it also shows promising possibilities for data processing in food
analysis, especially, foodomics. Thus, more and more deep learning approaches are used. This review
presents an introduction into deep learning in the context of metabolomics and proteomics, focusing
on the prediction of shelf-life, food authenticity, and food quality. Apart from the direct food-related
applications, this review summarizes deep learning for peptide sequencing and its context to food
analysis. The review’s focus further lays on MS (mass spectrometry)-based approaches. As a result of
the constant development and improvement of analytical devices, as well as more complex holistic
research questions, especially with the diverse and complex matrix food, there is a need for more ef-
fective methods for data processing. Deep learning might offer meeting this need and gives prospect
to deal with the vast amount and complexity of data.
Keywords:
deep learning; machine learning; metabolomics; food authenticity; food fraud; shelf-life;
peptide sequencing; mass spectrometry
1. Introduction
New challenges and the development or improvement of analytical methods in the
last years come with the need for new approaches enabling a holistic way to evaluate food
products [
1
,
2
]. Foodomics is not really a well-defined term being used to unite the analytical
technologies and disciplines of the omics-cascade with research questions in food and
nutrition [
1
,
3
]. Genomics, proteomics, and metabolomics are part of the so-called omics-
cascade, comprising disciplines, technologies, and methodologies that are commonly used
to describe the whole profile of food compounds [
4
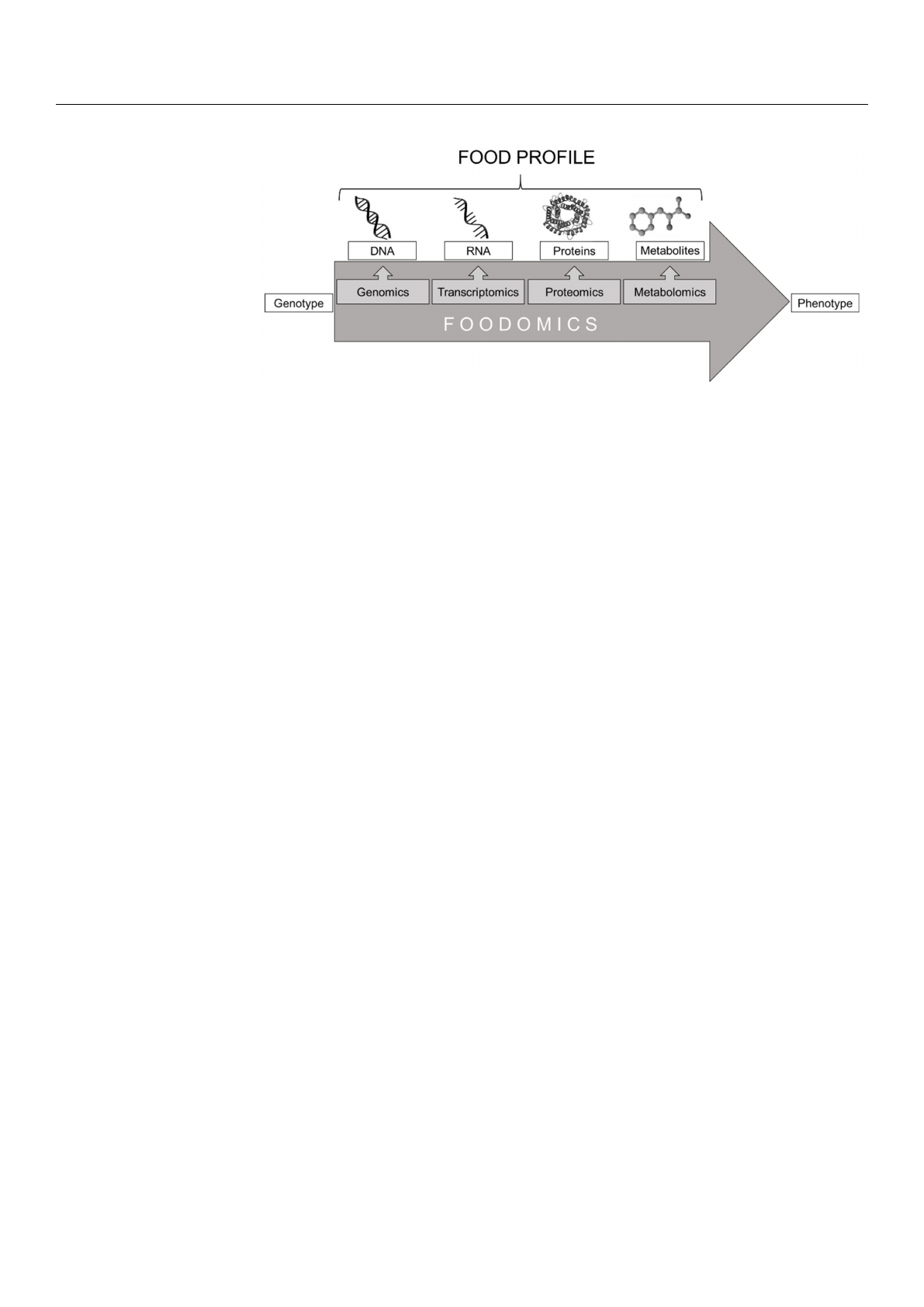
]. Figure 1illustrates schematically this
cascade. These applications are often also called high-throughput technologies, producing
a substantial amount of data [
5
–
7
]. Every discipline provides different information about
the composition of the target. As the analytical date collected is steadily increasing, a new
approach is the integration of a mathematical/bioinformatic point of view into foodomics.
The first discipline of the omics-cascade is genomics and focuses on the investigation of the
entire genome, meaning all genetic material of an organism based on the four bases DNA
code with its 64 codons, allowing a countless number of sequences. Because of the low
adaption to exogenous influence factors, the genome is predominantly stable and offers a
valuable tool for the differentiation and identification of species.
Foods 2021,10, 1803. https://doi.org/10.3390/foods10081803 https://www.mdpi.com/journal/foods
Foods 2021,10, 1803 2 of 18
Figure 1. Scheme of the omics-cascade.
Transcriptomics is the next discipline in the course of the omics-cascade and describes
the analysis of the transcriptome, which includes mRNA, non-coding RNA, as well as small
RNA in an organism [
8
]. The transcriptome is, unlike the genome, not stable and therefore,
almost unsuitable for analytical applications regarding food investigations, because of the
difficult dynamics [
4
]. The trancriptome leads to proteins. Proteomics describes the study
of all proteoformes in a defined biological system [
9
]. Nowadays, it seems to be almost
clear that the estimated number of genes (~100,000) is much higher than the anticipated
number identified: (~20,300) [
10
]. Moreover, this means that at the protein level, the
variations is much higher because of the encoded proteins, but also all kinds of follow-up
modifications [
11
]. Similar to other biological matrices, investigating the proteome of a food
product can be done with the following two strategies: On the one hand, the so called top-
down approach focuses on the characterization of intact proteins [
12
–
14
]. In contrast, the
bottom-up approach usually focuses on the peptides resulting from a proteolytic digestion
of the proteins [
13
,
14
]. Both targets—proteins and peptides—are analyzed afterwards
with mass spectrometry [
14
]. Metabolomics is the next discipline in the omics-cascade
and focus on the identification and quantification of the whole metabolome [
4
]. This
includes substrates and products of metabolic pathways and is directly associated to the so
called phenotype [
14
,
15
]. So, it is obvious that the metabolome is heavily influenced by all
kinds of exogenous factors. However, the metabolome enables an even more pronounced
fingerprint of a system, as many compounds can be taken into account for an evaluation
and a certain status of product at a certain timepoint can be estimated [4–7,14,16].
In the following, this review focuses primarily on proteomics and metabolomics, be-
cause those approaches are mainly mass spectrometry (MS)-based and the most prominent
disciplines for differentiating food products with regard to identification (‘authentication’),
but also characterizing the influence factors altering the phenotype (‘status’). The MS-based
methodologies offer a basis for many chemometric applications, especially with regard to
food analysis.
MS is the primary analytical technique to perform proteomics and metabolomics. It
is a technique for additionally separating molecules (besides chromatography), but with
regard to the mass-to-charge ratio (m/z) of an ion. However, in nearly all cases, MS-based
investigations of food are coupled with liquid chromatography (LC) or gas chromatography
(GC), where the analytes are additionally separated, with a certain clean-up, before entering
the mass spectrometer [
17
]. There are two combination methods for those applications:
on the one hand low-resolution mass spectrometry (LRMS) often provided as a triple-
quadrupole as an analyzer and on the other hand high-resolution mass spectrometry
(HRMS) with time-of-flight or similar detectors [12,18,19].
To describe the composition of food, HRMS technologies are applied preferably, as
these instruments provide the most efficient results, facing different challenges related
to the structure and quantity of molecules in natural products as well as processed food
products [17,18].

Foods 2021,10, 1803 3 of 18
HRMS makes it possible to also separate isobaric molecules [
18
]. Another impres-
sive aspect of this technology is that HRMS enables screening and quantifying without
a reference standard. In this context, a reference standard is the exact substance, which
is the target of an investigation. LRMS needs those references to identify the analytes.
With HRMS suspect screening and non-targeted applications can be performed, while
not needing references, because of a precise mass-to-charge-ratio and the generating of
other values like the collisions cross section (CCS) [
18
,
20
]. These reasons often led to
the conclusion that the superior choice to perform non-targeted approaches of complex
matrices is
HRMS [12,18,19,21,22].
However, these different omics provide lots of data.
Consequently, chemometric tools need to be developed and applied. The goal is to deal
effectively with the large amount of data, to achieve different assignments like the predic-
tion of shelf-life, identifying food fraud, proving food authenticity, and evaluating food
quality, in general [
23
,
24
]. The novel deep learning approaches might provide an adequate
tool for answering holistic food-related questions in the future and also grant even more
possibilities than the traditional applications.
2. Chemometrics, Artificial Intelligence, and Machine Learning
When dealing with this emerging topic, primarily some terms and concepts need to
be introduced to enable strategies and protocols for chemometrics. When starting with the
term Chemometrics itself, this has been defined by the International Union of Pure and
Applied Chemistry (IUPAC) as “The science of relating measurements made on a chemical
system or process to the state of the system via application of mathematical or statistical
methods.” [
25
,
26
]. This definition includes the combination of the disciplines chemistry,
mathematics, and computer science with the focus on the generated data.
Artificial Intelligence (AI) is an expression many stumble across regularly, but it
remains unclear what it really means or comprises. IUPAC defined AI as “The capability
of a machine to perform human-like intelligence functions, such as learning, adapting,
reasoning and self-correction.” [
27
]. Machine Learning (ML) is considered as a subclass
of AI, covering the methods of detecting and learning. Patterns need to be determined
and learning leads to optimization, and using these enables decision-making or predicting
future outcomes [
28
]. Deep Learning (DL) in turn is a certain form of ML, which is
presented in more detail in the next section. The relationship between AI, ML, and DL
is shown in Figure 2. A further term that is often mentioned in relation to the others is
Data Mining (DM). DM is a step of knowledge discovery in databases (KDD). The tools
used for DM are often ML tools. DM or KDD general focus on the knowledge discovery
including storage, access of data, as well as visualization; all in all, providing a workflow
for an evaluation process [29].
Figure 2. Relationship of artificial intelligence, machine learning, and deep learning [30].
Foods 2021,10, 1803 4 of 18
ML methods are categorized into supervised, unsupervised, and reinforcement learn-
ing. Supervised learning is based on labeling the training sets with the desired output. It is
the most common used technique. Common tasks in supervised learning are regression
and classification tasks. While classification tasks provide a categorical output, regres-
sion provides real-valued outputs. Unsupervised learning can be used for the discovery
of patterns in datasets (‘fingerprints’), where no labelling of data is given in advance.
Reinforcement learning is based on reward or punishment signals [28].
There are some issues that should be considered when ML methods are applied.
The training of supervised models is based on labelled data. These are processed and
fitted to improve performance. Accordingly, the efficiency of the model depends on the
used dataset. Limitations are inadequate small datasets, non-representative data, and an
insufficient quality of the datasets. While the model is trained, overfitting is a problem as
well. Overfitting means that the model performs well with the training data but difficulties
are occurring in generalizing or adapting the patterns observed to new data. Overfitting
can be caused by different reasons. One might be that the model has been trained using
the same data with too many repetitions. Another reason for overfitting is models which
are too complex for the given task. Moreover, it can also be caused by datasets that are
insufficient in representing the generality. Underfitting on the other hand results from
models that are too simple for a rather complex topic [31,32].
Some commonly used chemometric and ML models in foodomics are principle compo-
nent analysis (PCA) [
33
], partial least square-discriminant analysis (PLS-DA) [
34
], support
vector machine(s) (SVM) [
30
], random forest (RF) [
35
], decision tree (DT) [
36
], and k-nearest
neighbors (kNN) [37,38].
3. Deep Learning
Conventional machine-learning-systems need manual feature extraction, whereas DL
systems learn these features from the trainings data [
39
]. DL is learning of representation
of data through layers of neurons [
30
]. These neurons are structured in form of Neural
Networks (NN). As the name indicates, NN consist of artificial neurons. The first NN are
based on computational concepts that are structurally similar to biological neurons and on
how they might work together as a network [
31
]. Artificial neurons receive one or more
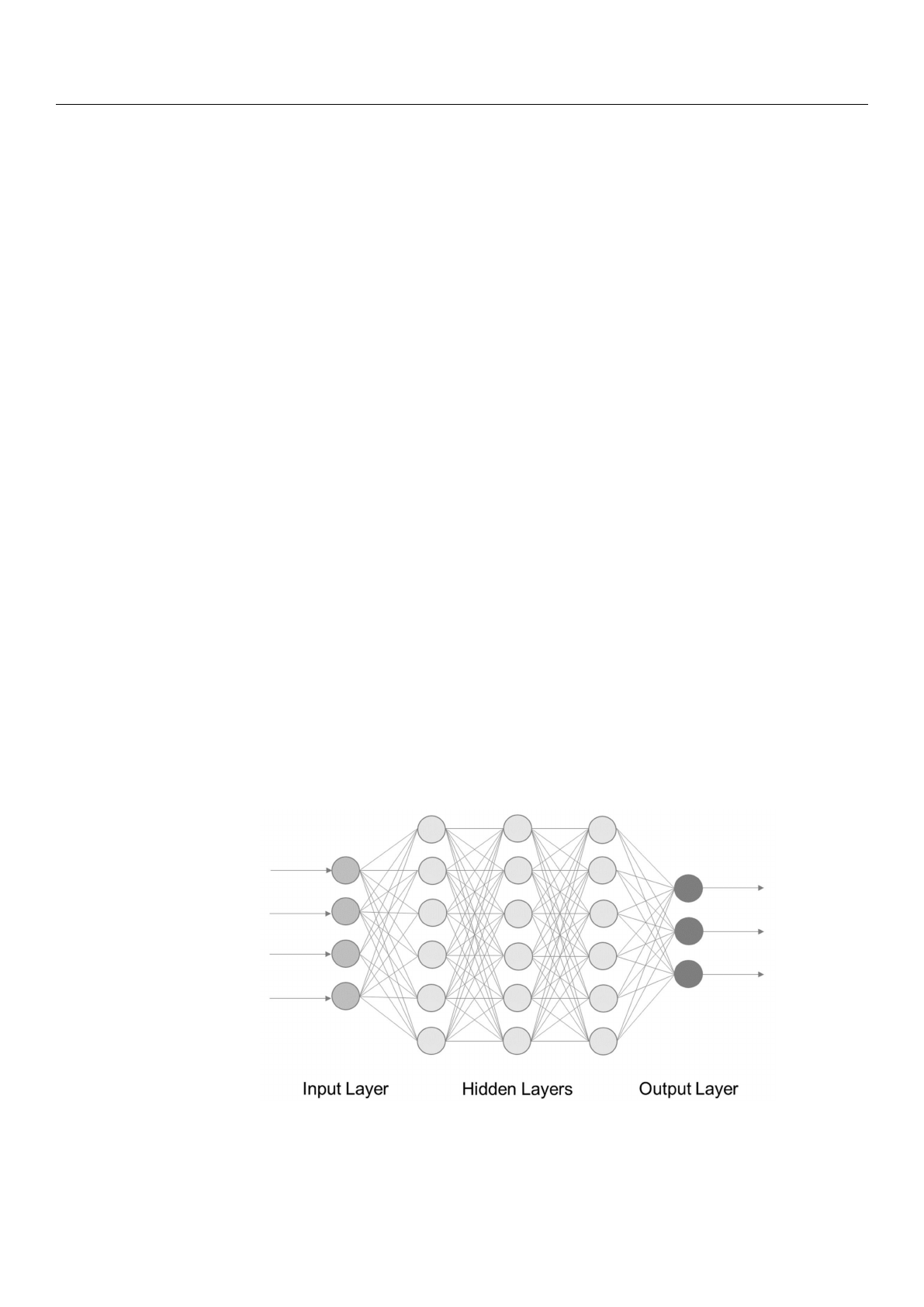
inputs, which can activate a neuron to give an output. Figure 3shows the structure of a
simple NN, also called multilayer perceptron (MLP) [30].
Figure 3.
Architecture of a feedforward neural network with four input neurons, and three output
neurons, and (here exemplarily three) hidden layers [40].
It is a feedforward neural network (FNN) that consists of three main components: the
neurons (also called nodes), the connection between these neurons, and the layers. The
layers and thereby the neurons are divided into input, hidden, and output [
39
]. The input

Foods 2021,10, 1803 5 of 18
neurons receive the raw data. Each of the varying number of hidden layer of neurons takes
the sum of the outputs of the preceding layer as an input. This input goes through an
activation function, generating output according to the value of the input [
39
]. DL is not
equal to NN, although it is often used in a similar way.
The differentiation between deep and shallow NN are based on the number of hidden
layers, but with no defined number of them [
31
]. NN are categorized in feedforward NN
(FNN) and recurrent NN (RNN). FNN are acyclic, as the data stream goes straight through
each layer from input to output [
41
]. In the previous section and Figure 3, a simple type of
FNN was described; a special kind of FNN that should be pointed out is the convolutional
neural network (ConvNet, CNN). It consists of one or more convolutional layers followed
by a pooling layer. While the convolutional layer detects features in the input matrix, the
pooling layer reduces the dimension. After convolutional and pooling layers are applied,
usually fully connected layers are used as well [
39
]. Recurrent neural networks (RNN) on
the other hand, are distinguished by feedback connections. Due to the feedback connection,
the output of the neuron is not only influenced by the current input of the neurons in
the preceding layer, but also by inputs from previous timepoints. The so-called hidden
state of the neurons provides a kind of memory from the previous layers. Therefore, RNN
are strong for processing sequential data [
31
,
42
]. The long short-term memory (LSTM)
is a variant of RNN, coping with the challenge of the loss of long-term information in
conventional RNN. The LSTM features so-called memory cells with three gates: input,
output, and forget gate. These enable the cells to extract and save important input in
long-term aspects [43].
The most used learning technique in DL is supervised [
39
]. Supervised, unsupervised,
and reinforcement learning have already been described above. Supervised learning uses
backpropagation. As already mentioned, labelled datasets are needed. The data is split into
training and testing data. The bigger part is used for the training of the model. Initially, the
output of a small dataset is calculated, then the error in comparison with the desired output
is considered, and subsequently the weights and biases are adjusted. This is performed
multiple times until the functions reaches a local minimum [39,44].
For the application and programming of DL algorithms, the most popular program-
ming languages are Python [
45
], R [
46
], and MATLAB [
47
].Frameworks like Tensor-
Flow [
48
] and PyTorch [
49
] can be used, making the application more accessible, due
to the simplified integration of models and various available tutorials, even with a lim-
ited background knowledge in informatics. Last but not the least, the improvement of
graphic processing units contributed to the success of DL in recent years. These enabled
the acceleration of the NN training [39,41].
4. Food Fraud and Food Authenticity
Food Fraud, Food Crime, Food Adulteration, and Food Terrorism are just a few terms
to describe different food safety issues that have been especially associated with authen-
tic food, which refers to a certain (production) technology, origin, or other specificities.
The European Commission describes food fraud as “any suspected intentional action
by business or individuals for the purpose of deceiving purchasers and gaining undue
advantages therefrom, in violation of rules referred to in Article 1 (2) of Regulation (EU)
2017/625 (the agri-food chain legislation)”. Food fraud includes, referring to the Food
and Drug Administration, economically motivated adulteration or the concept of food
counterfeiting [
50
,
51
]. This means that once the intentional violation against the food law
is committed, in most cases for achieving an economic or financial benefit, it is a matter of
food fraud, and the consumers are at risk of being cheated or even consumer’s health is in
danger [
50
,
52
]. There are different types to perpetrate food fraud as shown in Figure 4. One
subtopic is the non-approved enhancement of some food products. An example for that
is the so called “melamine scandal 2008” in China, where melamine was added to infant
formula and other food materials to enhance the protein value by mimicking proteins with
melamine as intense nitrogen-containing compound [
53
–
56
]. Another subtopic of food
Loading more pages...