
SCHWERPUNKTBEITRAG
https://doi.org/10.1007/s13222-022-00415-0
Datenbank Spektrum (2022) 22:131–141
NebulaStream: Data Management for the Internet of Things
Steffen Zeuch1,2 · Xenofon Chatziliadis1· Ankit Chaudhary1· Dimitrios Giouroukis1·PhilippM.Grulich
1·
Dwi Prasetyo Adi Nugroho1·ArianeZiehn
1,2 ·VolkerMark
1,2
Received: 4 February 2022 / Accepted: 2 May 2022 / Published online: 30 May 2022
© The Author(s) 2022
Abstract
The Internet of Things (IoT) presents a novel computing architecture for data management: a distributed, highly dynamic,
and heterogeneous environment of massive scale. Applications for the IoT introduce new challenges for integrating the
concepts of fog and cloud computing as well as sensor networks in one unified environment. In this paper, we present early
approaches that address parts of the overall problem space. All approaches are incorporated into NebulaStream (NES),
our novel data processing platform that addresses the heterogeneity, unreliability, and scalability challenges of the IoT and
thus provides efficient data management for future applications.
Keywords IoT · Streaming · Modern Hardware
1Introduction
Over the last decade, the amount of produced data has
reached unseen magnitudes. The International Data Cor-
poration [1] estimates that by 2025 the global amount of
data will reach 175ZB and that 30% of these data will
be gathered in real-time. Particularly the number of IoT
devices is expected to grow to 20 billion connected de-
vices [2], which are deployed in various application scenar-
ios, e.g. smart-cities [3] and traffic-monitoring [4]. At the
same time, devices such as embedded computers or mobile
phones continuously increase their processing capabilities.
The exploitation of their capabilities becomes essential to
handle the future data volumes of the IoT. As a result, the
IoT is one of the fastest emerging trends in the area of
information and communication technology [5].
The explosion in the number of connected devices trig-
gers the emergence of novel data-driven applications. These
applications require low latency, location awareness, geo-
graphical distribution, and real-time data processing on mil-
lions of data sources. To enable these applications, a data
Steffen Zeuch
firstname.lastname@tu-berlin.de
Volker Mark
firstname.lastname@dfki.de
1DIMA, TU Berlin, Einsteinufer 17, 10587 Berlin, Germany
2IAM, DFKI GmbH, Alt-Moabit 91c, 10559 Berlin, Germany
management system needs to leverage the capabilities of
IoT devices. To this end, data processing has to expand
beyond the cloud [6].
Today’s data management systems are not yet ready for
these applications. Systems based on the cloud paradigm,
e.g., Flink [7], Spark [8], and Kafka Streams [9] do not ex-
ploit the capabilities of IoT devices. These system require
the centralization of all data in the cloud prior to applying
any processing. For future IoT applications, this centralized
processing paradigm presents a bottleneck as it requires the
collection of data from millions of geo-distributed sensors.
This trend will not only impact typical IoT applications
like smart cities but also spread across the entire Smart-X
universe, e.g., smart city, smart grid, smart home. In ad-
dition, cloud-based services and even the HPC community
fundamentally neglect that the majority of interesting data
is produced outside the cloud [1,5]. Thus, the main ques-
tion for future system designs is how to enable analytics on
zettabytes of data produced outside the cloud from millions
of geo-distributed, heterogeneous devices in real-time.
Compared to the pure cloud-based systems, the IoT in-
troduces many significant changes that require new solu-
tions:
1. Hierarchical topology: IoT topologies follow a tree-like
structure. Where data moves from the sensors via inter-
mediate nodes to the cloud.
2. Geo-distribution: IoT devices expand the cloud and are
geo-distributed.
K

132 Datenbank Spektrum (2022) 22:131–141
3. Heterogeneous devices: Processing devices range from
low-end battery-powered sensors (e.g., Mica Motes)
over SoCs (e.g., Raspberry PIs) to high-end servers in
the could.
4. Moving devices: Devices outside the cloud are poten-
tially movable and change their position within the net-
work topology.
5. Sensor Management: Sensor data in IoT environments
have a fluctuating nature, which poses a challenge for re-
source-constrained devices that cannot easily cope with
the velocity and volume of incoming data.
To enable future IoT applications and address the intro-
duced changes, a data management system for the IoT has
to combine the cloud, the fog, and the sensors in a single
unified platform to leverage their unique advantages and
enable cross-paradigm optimizations (e.g., fusing, splitting,
or operator reordering). A unified environment introduces
a previously unprecedented, unique combination of char-
acteristics, e.g., hardware heterogeneity, unreliable nodes,
and changing network topologies.
This new set of characteristics enables new cross-
paradigm optimizations, which are crucial to support up-
coming IoT applications on top of millions of sensors.
Overall, there is no general-purpose, end-to-end data man-
agement system for a unified sensor-fog-cloud environment
with functionality similar to production-ready systems.
In this paper, we present early research results that ad-
dress parts of the overall problem space. All solutions are
designed for NebulaStream 1, our novel data processing
platform that addresses the heterogeneity, unreliability, and
scalability challenges of the IoT to enable efficient data
management. We will point out in the respective sections
what the current status of integration is. In detail, we present
the following approaches: In Sec. 2, we present a new Eco-
Join that allows NebulaStream to perform energy-efficient
joins on IoT devices. In Sec. 3, we present adaptive query
compilation, which allows resource-efficient stream pro-
cessing on a broad ranges of devices. In Sec. 4, we investi-
gate if state-of-the-art monitoring solutions are suitable for
IoT environments with millions of devices and how they
should be modified to improve their performance outside
the cloud. In Sec. 5, we introduce Governor, an operator
placement algorithm designed for the IoT. In Sec. 6,we
investigate complex event processing on top of the IoT and
propose new solutions for a unified fog-cloud environment
that fulfill the low-latency requirements of future IoT ap-
plications. In Sec. 7, we investigate adaptive sampling and
filtering as important techniques for large-scale sensor de-
ployments. With this paper, we present first research results
as results of our work on NebulaStream.
1https://nebula.stream
2 Energy Efficiency
IoT systems often offload data processing workload to edge
devices due to their proximity to data sources. In many
cases, these edge devices operate on a limited power and
energy budget, e.g., battery-powered. Hence, it is crucial to
take energy efficiency into account when designing a stream
processing engine (SPE) for the IoT.
Energy-efficient data management has been an active
research area over the few last years. Tsirogiannis et al.
[10] argued that energy efficiency can be improved through
a more optimized processing efficiency, such as by using
a more efficient algorithm. On an orthogonal dimension,
race-to-idle [11,12] exploits the capability of modern pro-
cessors to enter the low-energy idle state when there is no
work, e.g., by lowering the clock speed. Another line of
research utilize system-on-chip (SoC), such as energy-opti-
mized CPUs [13] and integrated GPUs [14] to deliver high
performance and low energy consumption.
Existing research in energy-efficient data management
focuses on processing workloads of relational databases.
However, the IoT and NebulaStream in particular bring
unique challenges that are not tackled by previous work.
2.1 EcoJoin
To tackle the energy efficiency challenges when process-
ing stream join workloads on IoT devices we proposed the
EcoJoin [15] for NebulaStream. In particular, EcoJoin ad-
dresses three aspects of IoT devices when handling en-
ergy efficiency. First, we exploit changing workload char-
acteristics. Second, we design a join algorithm to increase
high computational efficiency. Third, we utilize the avail-
able hardware to preserve energy utilization.
2.1.1 Exploiting Workload Characteristics.
EcoJoin adopts the idle-to-race approach to achieve energy-
efficient stream join processing. To exploit idle-to-race,
EcoJoin splits the processing of incoming event streams
into batches. In particular, EcoJoin applies a two-step ap-
proach: first, by setting the processor to enter an idle phase
when waiting for tuples in batches and second, by adjusting
the processor’s frequency to the value required to sustain
the current ingestion rate.
2.1.2 Increasing Computational Efficiency.
EcoJoin applies a symmetric hash join algorithm to achieve
higher throughput and energy efficiency compared to the
nested loop join algorithm that is used in state-of-the-art
stream join solutions. Adapting the symmetric hash join to
a streaming setup leads to two challenges. First, triggering
K
NebulaStream 133
the build and probe for each incoming tuple is inefficient.
Second, a full scan of the hash table to invalidate a tuple that
exceeds the range of the specified window is expensive. To
this end, EcoJoin implements a batching mechanism and
reduces the tuple invalidation overhead by only evicting
records if the hash table is close to its maximum capacity.
Under the hood, EcoJoin maintains two hash tables, i.e.,
one for each join side, and performs the join operation in
three phases. In the first phase, EcoJoin inserts tuples from
a batch that is ready processing into the corresponding hash
table, which is partitioned on the tuple’s key. In the second
phase, EcoJoin probes the batch from one side with the
hash table of the other join side. If a pair satisfy the join
predicate, EcoJoin emits the matching pair into a result
stream. In the third phase, EcoJoin deletes all invalid tuples,
i.e., tuples that are outside of the current window range
and thus will not find any match. To reduce the clean-up
overhead, EcoJoin counts invalid tuples and only triggers
the clean-up process periodically.
2.1.3 Exploiting Heterogeneous Processors.
EcoJoin leverages CPUs and integrated GPUs to maximize
energy efficiency. To this end, EcoJoin switches devices to
process the join based on their availability and under the
given workload.
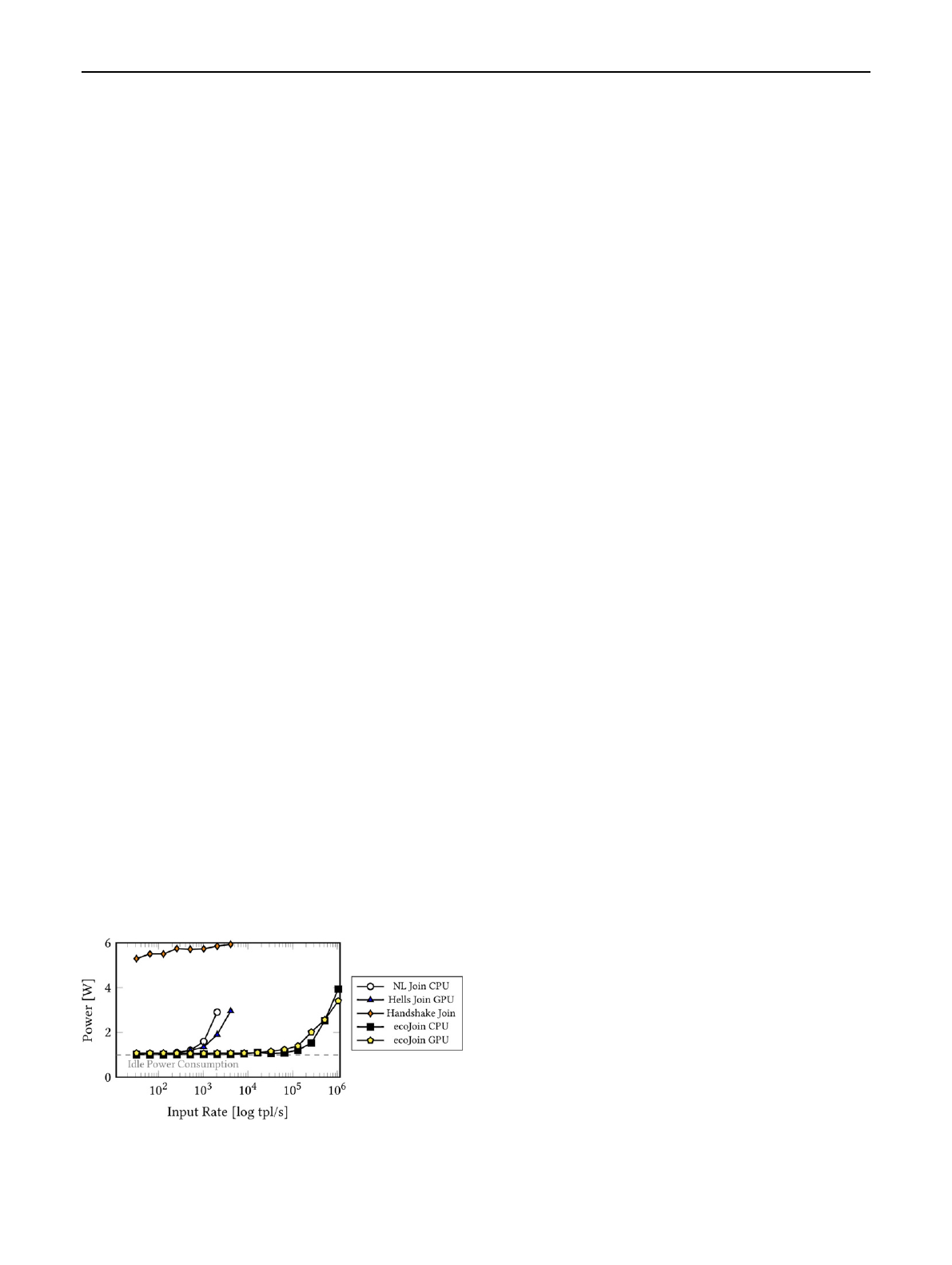
2.2 EcoJoin Evaluation
We evaluated the power consumption, throughput, and la-
tency of EcoJoin. To this end, we compared the throughput
and energy consumption of EcoJoin to existing stream
join algorithms, i.e., naive Handshake Join (CPU) [16]
and HELLS Join (CPU/GPU co-processing) [17]. Figure 1
shows the throughput and power consumption of the differ-
ent stream join algorithms. The x-axis shows the maximum
sustainable throughput of each algorithm. The CPU and
GPU variant of our EcoJoin achieve the highest through-
put compared to other algorithms, i.e., up to 1M tuples/s.
In contrast, the Handshake Join and HELLSJoin achieve
similar maximum sustainable throughput of 4K tuples/s,
Fig. 1 Power consumption of streaming joins
while the naive NLJ achieves only 2K tuples/s. On the
y-axis, we show the amount of power consumed by each
join algorithm. EcoJoin consumes significantly less energy
compared to other join algorithms for the same sustainable
throughput. In particular, EcoJoin shows up to 81% less
power consumption compared to Handshake Join and 65%
less compared to HELLS Join. In summary, the EcoJoin
outperforms state-of-the-art stream join algorithms in terms
of throughput and energy efficiency.
2.3 Summary
Energy efficiency is one of the most crucial aspects in of-
floading data processing workloads to edge devices in an
IoT data management system. We tackle this challenge
within EcoJoin by proposing an energy-efficient stream
join. In future work, we plan to integrate the approach that
we have in EcoJoin to NES and investigate the feasibility
of a similar approach for other stream processing operators
in general.
3 Efficient Stream Processing
Over the last years, the increasing demands of real-time
use-cases has led to a wide adoption of stream processing
workloads. These workloads execute long-running queries
over unbounded, continuously changing, high-velocity data
streams. State-of-the-art stream processing engines, e.g.,
Flink [7], and Storm [18], distribute processing to large
homogeneous compute clusters to achieve high-throughput
and low-latency’s. However, these systems are designed for
cloud environments and can not address the unique require-
ments of IoT scenarios. In particular, we observed in an ex-
perimental study three fundamental limitations of current
SPEs [19].
3.1 Low resource utilization.
Our study revealed that none of the existing systems were
able to fully utilize the available hardware resources. In
particular, they suffered from instruction cache misses as
they follow interpretation-based processing model and data
cache misses as they rely on managed runtimes. Conse-
quently, these systems are not suited for IoT environments,
which require efficient data processing on a wide range of
heterogeneous and resource-constrained devices.
3.2 Inefficient parallilization.
State-of-the-art SPEs utilize a key-by partitioning to dis-
tribute stream processing workloads uniformly across large
compute clusters. However, this strategy introduces an ex-
K

134 Datenbank Spektrum (2022) 22:131–141
pensive shuffle phase, which induces a high overhead per
node. Consequently, this strategy is not suited for low-end
and mid-end IoT devices with limited processing power.
3.3 Missed optimizations.
Current SPEs receive a query, apply optimizations, and de-
ploy an execution plan. However, stream processing queries
are inherently long-running. Thus, the data characteristic of
the input stream may change over the run time, which re-
duces the efficiency of a plan. As a result, current SPEs are
not designed to handle the dynamicity of the IoT.
To address these three limitations, NebulaStream lever-
ages adaptive query compilation [20].
3.4 Adaptive Query Compilation
In the following, we discuss NebulaStream’s adaptive query
compilation engine, which bases on Grizzly [20]. Grizzly
combines query compilation, task-based parallelization, and
adaptive optimizations to increase resource utilization.
Query compilation is a well-known technique for effi-
cient data processing in relational data processing engines
[21,22]. Grizzly adopts this approach for stream process-
ing and supports the unique properties of stream processing
queries. Within queries, Grizzly fuses operators to compact
code fragments and performs all operations in a single pass
over the data. Furthermore, Grizzly avoids serialization and
accesses data directly. As a result, query compilation based
on Grizzly increases code and data locality within NES.
Task-based parallelization enables the concurrent exe-
cution of operator pipelines [23,24] to fully utilize multi-
core CPUs. This eliminates the overhead of data pre-parti-
tioning but requires coordination between threads. To this
end, Grizzly introduces a lock-free window operator.
Adaptive optimizations enable a system to react to
changing data characteristics [25,26]. Grizzly monitors
data-characteristics, detects changes, and generates new
code variants at run time. This allows Grizzly to perform
speculative optimizations that exploit assumptions about
the incoming data. To mitigate profiling overhead, Grizzly
leverages hardware-performance counters to detect changes
in the data characteristics.
By leveraging these techniques within NebulaStream, we
improve execution performance significantly. Our results
show that Grizzly outperforms state-of-the-art SPEs by up
to an order of magnitude without losing generality.
3.5 Summary
NebulaStream applies adaptive query compilation to mit-
igate the limitations of state-of-the-art SPEs. As a result,
NebulaStream is able to fully utilize the available hardware
resources. In the future, we plan to extend NebulaStream
with support of UDFs [27] and concept drift detection [28].
4 Monitoring
SPEs apply optimizations to enable efficient data process-
ing at scale, e.g., state management [29], operator place-
ment [30–34], scheduling [35,36], query compilation [20],
adaptive sampling [37], and load shedding [38]. For optimal
decision making these approaches require accurate system
metrics of the underlying infrastructure as well as applica-
tions metrics of the running tasks. To provide these metrics,
SPEs need to monitor the infrastructure (e.g., available re-
sources on the devices, utilized bandwidth), detects node
failures, and measures the performance of internal work-
loads (e.g., operator throughput).
Managing the variety of metrics at scale in a highly dis-
tributed cloud-based SPE is in general a challenging task for
a monitoring system. Monitoring an SPE in an IoT environ-
ment exacerbates the challenge even further due to the geo-
distributed, heterogeneous, highly dynamic, and volatile na-
ture of IoT environments [39]. The collected metrics can
become quickly outdated due to device or network failures
and fluctuating load. While there exist several cloud-based
performance monitoring solution [40–42], there are no so-
lutions for IoT systems like NebulaStream.
In previous work [43], we analyzed two common ap-
proaches for performance monitoring in cloud-based SPEs
and investigate their applicability in large-scale IoT set-
tings. The first approach uses an external, general-purpose
monitoring system to monitor the performance of the SPE.
In contrast, the second approach implements monitoring
internally within the SPE. As the first approach is widely
adopted in industry, we experimentally evaluate whether it
can be applied efficiently in an IoT setting. Finally, based
on our analysis, we highlight the need to re-design moni-
toring frameworks for IoT data management systems and
sketch a set of requirements.
4.1 State of the Art
External monitoring systems such as Ganglia [40], Na-
gios [41], JCatascopia [44], the Elastic ecosystem [45]or
Prometheus [42] consist of four major components: mon-
itoring agents, monitoring server, data storage analytics &
visualization. Such frameworks monitor SPEs as follows:
1) the monitoring agents collects metrics from the nodes
of an SPE, 2) send the metrics to the monitoring server
for processing, and 3) transmit the processed metrics back
to the master node of the SPE. This solution has two ma-
jor drawbacks. On the one hand, it creates a strong de-
pendency between the SPE and an external system, which
K

NebulaStream 135
makes the dependent components harder to maintain in case
of changes. On the other hand, metrics have to cross multi-
ple system boundaries, i.e., from the SPE to the monitoring
system and back to the SPE, which creates an unnecessary
overhead [19].
To alleviate the inefficiencies of external monitoring
systems, some cloud-based SPEs like Flink, Spark, and
Storm implement their own monitoring internally. From
a high-level architectural perspective the monitoring of
cloud-based SPEs consists of the following common com-
ponents: metrics manager, SPE components, master node,
and external monitoring system. The metrics manager re-
trieves performance metrics from the Java Virtual Machine
(JVM) instance and from internal components of the SPE.
Afterwards, the metrics are forwarded to the corresponding
destinations, which can be components inside the workers
that require monitoring data, the master node, or external
systems. By introducing such a coupling of the monitoring
component, the SPE can avoid the additional overhead of
external monitoring systems and make monitoring more
efficient.
4.2 Requirements
Existing general purpose monitoring solutions can be seam-
lessly implemented and integrated in cloud-based SPEs that
use JVMs. There are many Java libraries that facilitate the
gathering of system and user metrics independently from
the underlying operating system and hardware. Data man-
agement systems for the IoT like NES are, however, im-
plemented in C++ due to its efficiency and suitability for
low-end devices [19]. Additionally, IoT environments are
more complex and diverse than the purely cloud-based en-
vironments, since they frequently undergo changes and con-
sist of many hierarchical levels with different networks and
permissions. As a result, not all devices can be connected
directly at all times.
In [43], we propose a list of requirements that are specifi-
cally tailored to an internal monitoring component for a data
management system for the IoT. Specifically, we identify
four categories of functional requirements that such a sys-
tem needs to satisfy in order to enable monitoring in IoT
environments: 1) performance optimization and scalability,
2) handling uncertainties, 3) permission and access control
and 4) handling heterogeneity. The first category addresses
the resource constrained environment and massive num-
ber of nodes properties. The second category addresses the
dynamic topology property. The third one handles the com-
plex networks property, and the last category addresses the
properties diversity.
4.3 Summary
In this section we explored existing monitoring solutions
with respect to their applicability in a stream processing
setting for IoT environments. We described the architec-
ture of SPE-external monitoring frameworks and provided
an overview of SPE-internal monitoring components. We
conclude that novel monitoring solutions are required to
support the distribution, heterogeneity, volatility, and com-
plexity of IoT environments.
5OperatorPlacement
An IoT infrastructure encompasses a large number of
heterogeneous, geo-distributed, and sparsely connected de-
vices [39]. These devices are capable of producing large
volumes of data that allow interesting real-time applica-
tions such as public mobility, health care, or manufacturing
[6]. These applications require IoT workloads which can
process massive amounts of real-time data to generate
new insights. The state-of-the-art solutions first collect
these large volumes of data centrally in the cloud and then
employ cloud-based frameworks such as, Flink or Spark,
for data processing. However, this central collection of
data leads to an increase in processing latency and overall
network, storage, and compute resources.
The resources available at and close to IoT devices in
the fog [46] infrastructure can mitigate these challenges by
performing in-network processing, such as partial-aggrega-
tion or filtering. This pre-processing allows reduction in the
overall data and further processing requirements. However,
holistic computation of data is not possible within the fog
infrastructure due to unavailability of data from IoT devices
in an isolated network zone.
A unified fog-cloud infrastructure allows mitigating the
challenges of increased resource consumption at cloud in-
frastructure and inability of performing holistic computa-
tions at fog infrastructure. In particular, by unifying the
cloud and fog infrastructure we can enable real-time pro-
cessing of data and efficient utilization of underlying het-
erogeneous and geo-distributed resources.
An IoT workload can have different application ob-
jectives, such as infrastructure monitoring, time-sensitive
anomaly detection, or fault-tolerant billing information col-
lection. The heterogeneity and volatility in the network and
compute resources in this unified fog-cloud infrastructure
presents unique challenges for achieving these application
objectives. A common challenge in such unified infrastruc-
ture is to perform placement of operators from a workload
to leverage the unique infrastructure properties and the
workload Service Level Objectives (SLOs), e.g., high-
throughput, low resource consumption.
K
Loading more pages...