
From Theory to Comprehension: A Comparative Study of
Differential Privacy and 𝑘-Anonymity
Saskia Nuñez von Voigt
Technische Universität Berlin
Berlin, Germany
Luise Mehner
Technische Universität Berlin
Berlin, Germany
Florian Tschorsch
Technische Universität Dresden
Dresden, Germany
ABSTRACT
The notion of
𝜀
-differential privacy is a widely used concept of
providing quantifiable privacy to individuals. However, it is unclear
how to explain the level of privacy protection provided by a dif-
ferential privacy mechanism with a set
𝜀
. In this study, we focus
on users’ comprehension of the privacy protection provided by
a differential privacy mechanism. To do so, we study three vari-
ants of explaining the privacy protection provided by differential
privacy: (1) the original mathematical definition; (2)
𝜀
translated
into a specific privacy risk; and (3) an explanation using the ran-
domized response technique. We compare users’ comprehension of
privacy protection employing these explanatory models with their
comprehension of privacy protection of
𝑘
-anonymity as baseline
comprehensibility. Our findings suggest that participants’ compre-
hension of differential privacy protection is enhanced by the privacy
risk model and the randomized response-based model. Moreover,
our results confirm our intuition that privacy protection provided
by 𝑘-anonymity is more comprehensible.
CCS CONCEPTS
•Security and privacy
→
Usability in security and privacy;
Data anonymization and sanitization; • General and reference
→
Surveys and overviews.
KEYWORDS
differential privacy, explanatory model, study
ACM Reference Format:
Saskia Nuñez von Voigt, Luise Mehner, and Florian Tschorsch. 2024. From
Theory to Comprehension: A Comparative Study of Differential Privacy
and
𝑘
-Anonymity. In Proceedings of the Fourteenth ACM Conference on
Data and Application Security and Privacy (CODASPY ’24), June 19–21, 2024,
Porto, Portugal. ACM, New York, NY, USA, 12 pages. https://doi.org/10.1145/
3626232.3653261
1 INTRODUCTION
Privacy-preserving techniques have been proposed in various do-
mains to provide data protection guarantees. The aim of these tech-
niques is to minimize the risk of identifying an individual while
also maximizing the utility of the data. One simple method is to
This work is licensed under a Creative Commons Attribution-
NonCommercial-NoDerivs International 4.0 License.
CODASPY ’24, June 19–21, 2024, Porto, Portugal
© 2024 Copyright held by the owner/author(s).
ACM ISBN 979-8-4007-0421-5/24/06
https://doi.org/10.1145/3626232.3653261
remove or generalize attributes so that each combination of at-
tribute values comprises at least
𝑘
entries, leading to the concept of
𝑘
-anonymity [
27
]. Each individual in the data set is therefore indis-
tinguishable from
𝑘−1
other individuals. However,
𝑘
-anonymity
does not provide strong mathematical privacy guarantees, as at-
tribute values can be revealed in some situations [16, 18].
The privacy concept of
𝜀
-differential privacy [
4
], offers stronger
privacy guarantees. It is a mathematical definition in which ran-
domization is used to limit the impact on the output of an individual
contributing to a database. The privacy parameter
𝜀
determines the
privacy-utility tradeoff.
It is, however, difficult for a user to comprehend the level of
privacy protection provided to them resulting from a particular
𝜀
.
Previous works have attempted to explain differential privacy mech-
anisms [
3
,
31
], quantify privacy guarantees [
10
,
15
,
21
], and com-
municate privacy risks [
1
,
7
]. One approach to making the privacy
parameter of differential privacy more comprehensible is to trans-
late
𝜀
into a corresponding privacy risk, expressed as a percent-
age [
15
,
20
]. Another approach has used the randomized response
technique [
30
] to describe privacy protection [
1
]. This technique in-
volves local differential privacy, which has been shown to be more
intuitive [
31
]. However, it is unclear whether these approaches
enhance users’ comprehension of the implications of differential
privacy mechanisms [3].
In contrast, for
𝑘
-anonymity, the privacy parameter
𝑘
is di-
rectly linked to individual identifiability. We therefore argue that
𝑘
-
anonymity is easier to understand than privacy protection provided
by differential privacy. Based on our assumption, we investigated
how we can explain the level of privacy protection of differential
privacy. Namely, in such a way that it is possibly just as compre-
hensible as 𝑘-anonymity.
To that end, we present three explanatory models that explain
the privacy protection provided by differential privacy. In each
explanatory model, we use a particular translation of the privacy
parameter
𝜀
into a more intuitive concept. These translations of
𝜀
describe the level of privacy protection, making it easier to compre-
hend the implications of various differential privacy mechanisms.
We build upon existing and established strategies to communicate
the privacy protection provided by differential privacy quantita-
tively; (1) the original mathematical definition (
DEF
); (2)
𝜀
as a
privacy risk (
RISK
); and (3) an explanation using the randomized
response technique (
RRT
). We conducted an experimental study
to investigate whether these explanatory models enhance users’
comprehension of differential privacy protection.
221

CODASPY ’24, June 19–21, 2024, Porto, Portugal Saskia Nuñez von Voigt, Luise Mehner, & Florian Tschorsch
In our experimental study, we examined users’ comprehension
of the privacy protection provided by a differential privacy mecha-
nism compared to their comprehension of the privacy protection
provided by a
𝑘
-anonymity mechanism. We thus anchor the compre-
hension of the privacy protection of differential privacy in general
and the respective comprehensibility with each explanatory model
to the comprehensibility of
𝑘
-anonymity. Our comparison increases
the methodological validity of our study. Importantly, we do not
compare the two mechanisms themselves nor their level of privacy
protection. Instead, we are interested in the comprehensibility of
privacy protection provided by the mechanisms.
With our results we provide evidence that the privacy protection
provided by differential privacy is best understood using
RRT
as
an explanatory model. Moreover, we establish
𝑘
-anonymity as a
baseline and an easily understandable privacy mechanism.
The paper’s contribution and structure can be summarized as fol-
lows: We present three explanatory models that include translations
of the privacy parameter to help users understand privacy protec-
tion and thus the implications provided by a differential privacy
mechanism in Section 2. After designing and conducting an exper-
imental study addressing our research questions (Section 3), we
performed a pilot study to validate our explanations and questions
before conducting our main study. Our improvements designed to
increase the internal validity of the questions concerning subjec-
tive and objective comprehension for the main study are presented
in Section 4. In our main study, we examined the participants’
subjective and objective comprehension of the differential privacy
protection with the explanatory models
DEF
,
RISK
, and
RRT
com-
pared to users’ comprehension of the privacy protection provided
by a
𝑘
-anonymity mechanism (Section 5). Lastly, we discuss limita-
tions and future work in Section 6 and we review related work in
Section 7. We conclude our paper in Section 8.
2 EXPLANATORY MODELS
In this section, we provide three explanatory models for the im-
plications of the privacy parameter
𝜀
of our privacy mechanism—
differential privacy. Each model involves a translation of the pri-
vacy parameter into a more intuitive concept. Each translation is
designed to help users understand the level of privacy protection
provided with a specified privacy parameter and thus the implica-
tions of the mechanism. In addition, we give a brief overview of
the privacy parameter of 𝑘-anonymity.
2.1 Privacy Protection of 𝑘-anonymity
The privacy protection of
𝑘
-anonymity [
27
] relies on the concept
of anonymity sets. An anonymity set is a set of elements which
are indistinguishable from each other. The individual’s entries in a
database are generalized or suppressed in a way that for each entry,
there are at least
𝑘
entries with the same values in all columns
that might be used to re-identify an individual. In other words,
individual’s entries are clustered into anonymity sets.
The privacy parameter
𝑘
translates to the size of the smallest
anonymity set in the database. The higher
𝑘
, the more indistinguish-
able individuals exist in each group, resulting in a stronger privacy
protection. For instance, with
𝑘=4
, the chance of correctly linking
an entry of a group to an individual is 1/4=0.25.
2.2 Differential Privacy Definition (DEF)
Differential privacy [
4
] bounds the amount of influence a single
individual’s data can have on the output of a statistical computa-
tion over a database. A mechanism
M
is
𝜀
-differentially private
if for any two neighboring data sets (
𝐷1
and
𝐷2
), differing in one
individual, and any statistical result computed over the data sets
(𝑆⊆Range(M)) satisfy:
𝑃[M(𝐷1) ∈ 𝑆] ≤ e𝜀𝑃[M(𝐷2) ∈ 𝑆]. (1)
The maximum distance between the probabilities of the mecha-
nism returning the result with each database is less than a certain
quantity. This quantity is based on the privacy parameter
𝜀
. A pri-
vacy parameter closer to zero reduces the maximum distance, which
means that the amount of influence any one individual’s data can
have on the overall output is smaller. A smaller privacy parameter
thus yields stronger privacy protection.
The privacy parameter
𝜀
translates into the factor by which
the probability of returning any other result is greater than the
probability of the same result if an individual is missing from the
data set. For instance, with
𝜀=ln 3
, thus,
eln 3 =3
the probability
of returning any result is at most three times the probability of the
same result if one individual is missing in the data set.
2.3 Epsilon as Privacy Risk (RISK)
Lee and Clifton [
15
] proposed for the Laplacian differential privacy
mechanism, a way of calculating the risk of users in a data set being
identified. In this framework, after an adversary receives an output
of the differential privacy mechanism, she then imagines every
possible scenario for a distribution of all possible values for the
individuals’ data that she does not already know. These scenarios
are her so-called possible worlds. By comparing the probability of
the mechanism returning the particular result for each possible
world, the adversary decides which possible world is most likely
to be true. The probability of the mechanism indicating the correct
possible world when returning a result hence represents the users’
risk of being identified.
Mehner et al. [
20
] simplified the framework by assuming worst-
case values for some variables, so that the risk of being identified
in a data set 𝑝depends only on 𝜀and 𝑛:
𝑝=
1
1+e−𝜀(𝑛−1), (2)
where
𝑛
corresponds to the number of (unknown) possible worlds
imagined by the adversary. Thus, the privacy parameter can be
translated into a privacy risk in percent.
However, the number of possible worlds
𝑛
may be difficult to
grasp. Moreover,
𝑛
depends on multiple often unspecified variables,
such as the knowledge of the adversary, the number of individuals
in the database and the number of possible values for an answer.
According to Mehner et al. [
20
], assuming the worst-case attack
scenario, an adversary might have only two possible worlds. For
example, she may be uncertain about only one individual’s answer
and there may be only two possible values for that answer. Accord-
ingly, the worst-case value for
𝑛=2
resulting in the global privacy
risk:
𝑝=
1
1+e−𝜀. (3)
222

From Theory to Comprehension: A Comparative Study of Differential Privacy and 𝑘-Anonymity CODASPY ’24, June 19–21, 2024, Porto, Portugal
We can therefore translate the privacy parameter for a given
𝜀
into the privacy risk of identifying the true answers of individuals
included in the database. In other words, if an adversary queries
the answer of an individual and there are only two possible answer
values (i.e., in a worst-case attack scenario), we can determine the
probability of the mechanism indicating the true answer of the
individual for a specified
𝜀
. For example, assume we set
𝜀=ln 3
,
which yields a privacy risk of
75
%, i.e., in the worst-case attack
scenario, the true answer of a person included in the database is
revealed with a probability of 75 %.
2.4 Using Randomized Response (RRT)
The number of possible worlds
𝑛
of Equation (2) is similar to the
number of different answers in the randomized response tech-
nique [
30
]. The randomized response technique is an approach
designed to provide plausible deniability to data subjects. The idea
is that some of the data subjects will give their true answer and
others will give a forced answer. The decision of whether an indi-
vidual gives a true or a forced answer is made randomly. Conse-
quently, each answer has a probability of being an individual’s true
answer. Therefore, users’ answers do not reveal the individuals’
true answers with certainty. The randomized response technique
inherently holds the local differential privacy guarantee.
More precisely, with a probability of
𝑝𝑡𝑟𝑢𝑒
, the true answer
𝑎
is
stored in the database. The probability of any false answer
𝑎0≠𝑎
is
𝑝𝑓 𝑎𝑙𝑠𝑒 =(1−𝑝𝑡𝑟𝑢𝑒 )/(𝑑−1)
, where
𝑑
is the number of possi-
ble answers. This mechanism is one approach of the randomized
response, called unary encoding, and it satisfies local differential
privacy:
𝑃[M(𝑎)=𝑎] ≤ e𝜀𝑃[M(𝑎)=𝑎0](4)
𝑝𝑡𝑟𝑢𝑒 e−𝜀=𝑝𝑓 𝑎𝑙𝑠𝑒 , (5)
resulting in
𝑝𝑡𝑟𝑢𝑒 =
1
1+e−𝜀(𝑑−1). (6)
The probability of storing a true answer is equal to the privacy
risk Equation (2), where the number of possible worlds
𝑛
corre-
sponds to the number of different answers 𝑑.
Hence, we can translate the privacy parameter
𝜀
into the probabil-
ity with which the mechanism stores a true answer in the database.
For example, assume we set
𝜀=ln 3
and have two possible an-
swers (
𝑑=2
). As a result, the probability of storing the true answer
is
75
%. With a higher number of possible answers, e.g.
𝑑=28
, the
probability of storing the true answer decreases to
10
%. Note that
the model also works for real-valued (continuous) data. In this case,
the worst case with
𝑑=2
should be used. The result indicates the
probability of storing true answers, regardless of whether the data
is discrete or continuous.
3 METHODOLOGY
In this section, we present and justify our hypotheses we formulated
to design our study. In addition, we detail how participants were
instructed, describe our sample, how we conducted the study and
how we analyzed the data.
Syntactic anonymization models, such as
𝑘
-anonymity, were
originally designed for privacy-preserving data publishing [
2
]. Dif-
ferential privacy, on the other hand, is more suitable for privacy-
preserving data mining. The concept of privacy-preserving data
publishing usually assumes a non-expert data publisher, i.e., the data
publisher does not have the knowledge to perform data mining [
9
].
Given that
𝑘
-anonymity is a viable solution for privacy-preserving
data publishing, the mechanism of
𝑘
-anonymity is aimed at the
non-expert who is the end user of the model. With
𝑘
-anonymity as
as simple and intuitive model [8], we derive our first hypothesis:
(H1)
Differential privacy vs.
𝑘
-anonymity: The privacy protection
provided by
𝑘
-anonymity is easier to comprehend than the
privacy protection provided by differential privacy (indepen-
dent of the explanatory model).
The definition of differential privacy is complex. Therefore, it is
important to describe the techniques or the implications of a differ-
entially private mechanism.
RRT
has often been used as an intuitive
mechanism [
1
,
26
]. Previous work has shown that
RRT
provides
more understanding among users [
1
,
31
].
RISK
was developed as an
intuitive explanation of
𝜀
. Consequently, we derive the following
hypothesis:
(H2)
Explanatory models: The explanatory models
RRT
and
RISK
will provide a better comprehension of the privacy protection
than the DEF model.
Previous work has shown that both numeracy skills and level
of educational affect risk understanding [
7
,
12
]. Users with low
numeracy skills have difficulty understanding risk in general [
12
].
These findings from previous work lead us to our final hypothesis:
(H3)
Education level and numeracy skills: High levels of educa-
tion and high numeracy skills help users to comprehend the
privacy protection provided by differential privacy.
3.1 Measures
Participants answered questions to evaluate their subjective and
objective comprehension of privacy protection. We also included
measures for covariates: demographics, privacy concerns and nu-
meracy skills.
3.1.1 Comprehension. Similar to previous work [
26
,
31
], we evalu-
ate the subjective comprehension (perceived comprehension) and
objective comprehension (actual comprehension) of the
𝑘
-anonymity
explanation and our explanatory models of the privacy protection
provided by differential privacy (RISK,RRT, and DEF).
We designed the questions concerning comprehension from
scratch, using direct questions. We included three 7-point-Likert
scaled questions regarding how the participants subjectively com-
prehended the level of privacy protection that each mechanism (and
its respective privacy parameter) provided. Following the questions
concerning subjective comprehension, there were four questions
testing the participants’ objective comprehension of privacy pro-
tection. In addition, we gave the participants the possibility to
comment on their comprehension answers. Last, we asked partici-
pants to directly compare which privacy mechanism they felt was
most comprehensible and intuitive in terms of privacy protection.
223
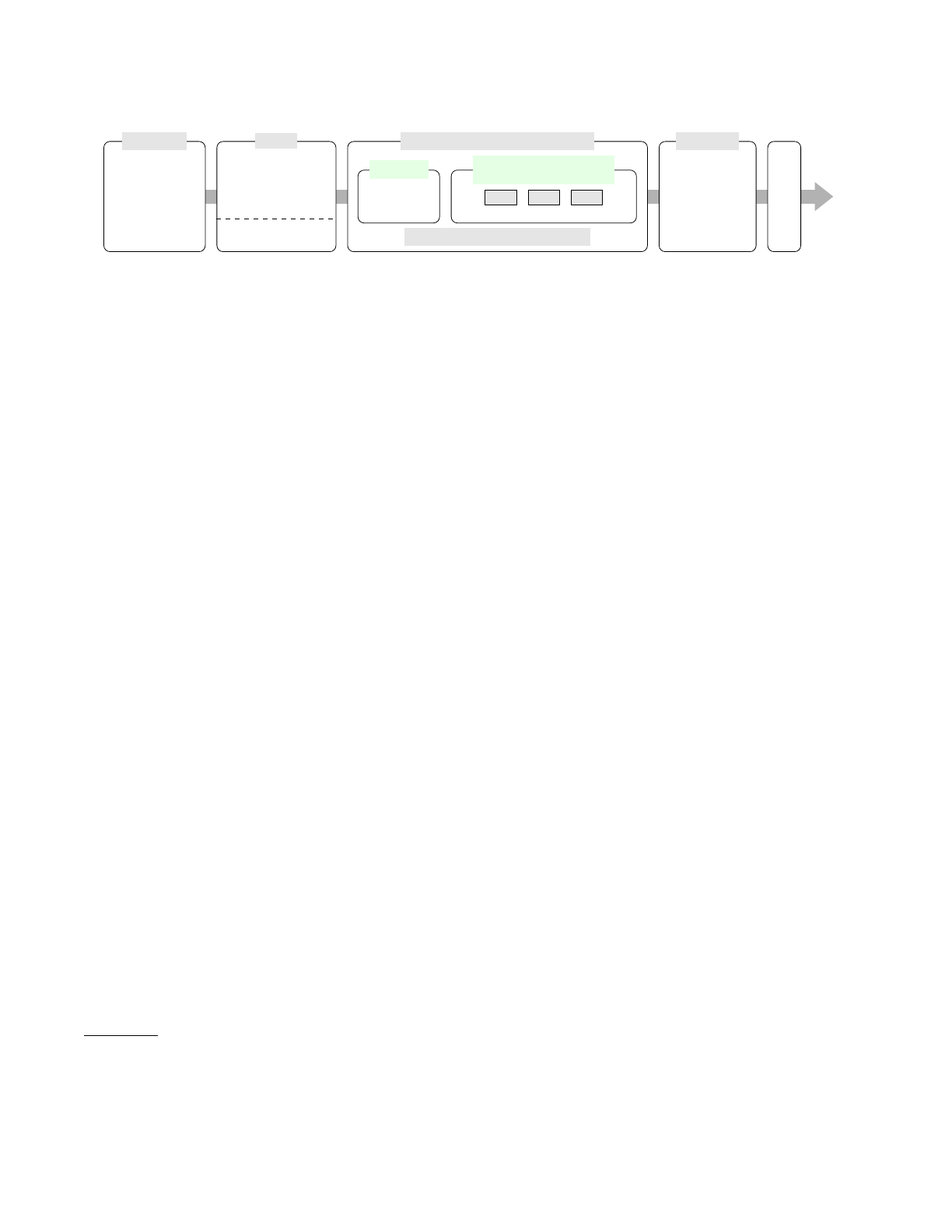
CODASPY ’24, June 19–21, 2024, Porto, Portugal Saskia Nuñez von Voigt, Luise Mehner, & Florian Tschorsch
Demographics
age,
field of study,
current level
of education
Scenario
statistics drug use
at school; parents
should not infer their
son/daughter’s drug use
comprehension questions
Privacy Protection Explanations (within-subject)
differential privacy
(between-subject)
RISK RRT
DEF
objective and subjective questions
𝑘-anonymity
objective and
subjective questions
direct comparison
Numeracy . . .
numeracy
privacy experience
privacy concerns
Check question
Figure 1: Overview of the study design.
3.1.2 Covariates. We assessed the participants’ numeracy skills
using subjective rating and objective test questions. The numeracy
questions were taken from multiple validated numeracy assess-
ments found in the literature [
6
,
17
,
25
]. Moreover, we asked about
any previous experience with privacy mechanisms in general and
differential privacy in particular. Finally, we also assessed the par-
ticipants’ general privacy concerns using a set of questions adapted
from Malhotra et al. [
19
]. We used these questions in the categories
of collection and awareness. We also included “attention” check
questions as part of the privacy aptitude and at the end of the study
to exclude inattentive participants: Please select 3 (More or less agree)
for this question and What is
4+5
?
1
. We assume that those par-
ticipants who were motivated at the end of the survey were also
motivated at the beginning.
3.2 Scenario and Explanations
We defined a fictional scenario about drug use at school as a running
example of a setting where privacy is crucial and where privacy
protection needs to be well understood at the same time. A school
stores student answers to a questionnaire on drug use in a database
grouped by age and class. In order to raise awareness, parents can
query the database, which is protected with a privacy mechanism.
Our explanations are designed from scratch. We used text-based
explanations because we focused on evaluation of the explanatory
model, not on how it was communicated. Our explanations start
with a short description of the privacy mechanism, inspired by
the Techniques description of Cummings et al. [
3
]. This was fol-
lowed by an explanation of the privacy protection parameter, e.g.
𝑘
, difference (
DEF
), risk (
RISK
) and probability (
RRT
). Finally, we
applied these explanations to our scenario and provided concrete
examples. The exact wording of our explanations can be found in
Appendix A.1.
3.3 Experimental Process
Prior to the main study, we conducted a pilot study to increase the
validity of our study questions. In particular, the pilot study allowed
us to validate our questions, explanations and instructions in terms
of textual clarity and general comprehensibility. We summarize the
results of the pilot study and the induced changes in Section 4.2
3.3.1 Overview of the Study Design. In Figure 1 we present an
overview of our study design and procedure. The process and design
1
We believe that this mathematical operation does not relate to numeracy because of
its simplicity. When answered, the question was answered correctly by all participants
of our main study.
2
The explanations, questions on subjective and objective understanding and
anonymized tables can be found in http://arxiv.org/abs/2404.04006.
of the main study and the pilot study, were the same. Both studies
had a mixed design with a between-subject factor “explanatory
model” (for differential privacy protection with three conditions
RISK
,
RRT
, and
DEF
) and a within-subject factor with two levels
(“privacy protection provided by
𝑘
-anonymity” and “privacy pro-
tection of differential privacy”). The within-subject factor included
in our study allowed us to evaluate the comprehensibility of differ-
ential privacy protection with each explanatory model compared
to the comprehensibility of the privacy protection of
𝑘
-anonymity.
As a results, we were able to
(1)
verify whether the privacy protection of
𝑘
-anonymity is
indeed easier to comprehend than that of differential privacy,
(2)
anchor the comprehensibility of differential privacy protec-
tion with each explanatory model to the comprehensibility
of privacy protection of
𝑘
-anonymity as a baseline for the
best possible comprehensibility,
(3)
control for any interindividual differences in comprehension
skills between the three conditions.
Moreover, use of a within-subject design reduced the standard
deviation in the objective and subjective comprehension scores,
improving the statistical validity of our study.
After a short welcome text explaining the purpose of the study,
the participants were asked to provide some demographic infor-
mation about themselves (age, field of study and current level of
education). Next, we introduced our fictional scenario. We ensured
that the participants understood the scenario by asking three check
questions: 1) Who provides the database in the scenario? 2) What
kind of data is stored in the database? 3) Eve (the adversary) wants
to find out the data of whom?
3.3.2 Procedure of Explanations. After ensuring that the partic-
ipants had read and understood the scenario, each participant
was presented with explanations of the privacy protection of two
privacy-enhancing mechanisms, an explanation of
𝑘
-anonymity
and an explanation of differential privacy. To control for learning
and other sequence effects, the order of the two explanations and
their respective comprehension questions were balanced. In other
words, participants were randomly assigned to either the first order
group, where the explanation and questions for
𝑘
-anonymity were
presented first, or to the second order group, where the explanation
and questions of the differential privacy protection were presented
first. Since each participant read and answered the questions for the
two explanations, our study had a within-subject factor with the
privacy protection of differential privacy and the privacy protection
of 𝑘-anonymity as factor levels.
224

From Theory to Comprehension: A Comparative Study of Differential Privacy and 𝑘-Anonymity CODASPY ’24, June 19–21, 2024, Porto, Portugal
The explanation of the privacy protection of
𝑘
-anonymity was
the same across all conditions. Each participant randomly (uni-
formly distributed) received one of the three explanations (
RISK
,
RRT
, or
DEF
) for differential privacy protection, resulting in three
between-subject conditions for the factor “explanatory model for
differential privacy protection”. We used similar phrasing and word-
ing in all explanations, including the explanation of the privacy
protection of
𝑘
-anonymity, in order to compare the comprehension
of the explanation. In addition, the subjective as well as the objective
comprehension questions were identical for each explanation.
The level of privacy protection provided by the differential pri-
vacy mechanism, i.e., the privacy parameter
𝜀
, was the same in each
explanatory model. We wanted to rule out the possibility of the level
of privacy protection systematically interfering with the partici-
pants’ comprehension of differential privacy protection. However,
differential privacy assumes a stronger adversary than
𝑘
-anonymity
does. A
𝑘
-anonymity mechanism cannot provide an equally strong
privacy protection as the differential privacy mechanism explained
using the
RISK
,
RRT
, and
DEF
explanatory models in our scenario.
Therefore, we have to trust that the weaker privacy protection did
not interfere with the participants’ comprehension. Consequently,
in our study, we explain the privacy protection of
𝑘
-anonymity with
𝑘=4
. We believe that this is an appropriate value to explain the
privacy protection of
𝑘
-anonymity since this results in a probability
of being identified of
0.25
. Again, we emphasize that we cannot
match the privacy levels of the two mechanisms.
3.3.3 Procedure after Explanations. After providing both the expla-
nations and the questions about their comprehensibility, we asked
participants directly about which privacy mechanism (if any) was
more comprehensible with respect to the level of privacy protection
and why. We also asked which mechanism (if any) they regarded
as providing a greater privacy protection in the particular scenario,
and why. The latter question was implemented to gain a deeper
insight into whether the participants had gained a sense of the rela-
tionship between a particular privacy parameter and the respective
level of privacy protection provided by each mechanism.
3.4 Participant Recruitment and Attributes
Both the pilot study and the main study were implemented us-
ing LimeSurvey
3
and emailed to university students of Berlin.
4
Our main study was publicly available between February 8 and
22, 2023. The participation was voluntary and we did not offer any
remuneration.
We used a set of questions provided by the Ethics Commission of
TU Berlin to self-evaluate the ethical considerations of the planned
research project. We then decided that a detailed application to the
Ethics Committee was not necessary. However, to address potential
ethical issues, we informed the participants (of the pilot study and
main study) about our data policies in our invitation email before
the survey: The evaluation of the responses would be anonymized,
i.e., we only used the LimeSurvey Response ID as an identifier and
3www.limesurvey.org
4
We cannot exclude the possibility of participants who participated in both studies.
However, the pilot study took place one year earlier, so we assume that the effect
is negligible. In addition, participants were asked about their prior knowledge of
privacy, so the overlap was controlled in the results of participants without any prior
knowledge.
would remove it before the statistical analysis. We only accessed
the results of the pilot study that were necessary to validate our
explanations and questions.
For the participants, the purpose of our study was to evaluate
explanations of the privacy protection provided by two privacy-
enhancing mechanisms. At that point, we did not refer to differential
privacy protection as the focus of our study to avoid the influence
of demand characteristics or participant expectations about our
desired outcome of the study. All participants were presumed to
have at least a high school diploma and to be currently studying at
a university.
There were a total of
249
respondents in the main study. Of these,
only
93
participants answered the subjective and objective com-
prehension questions for both explanations and could therefore be
included in the analysis. Of these, three participants were excluded
because they gave an incorrect answer to one of the comprehension
questions regarding the scenario or because they answered one of
the attention-check questions incorrectly, resulting in a total of
90
analyzed participants. Of these,
78
participants fully completed the
study and thus answered all questions. We decided to nevertheless
include the other
12
participants who did not finish the study into
parts of our analysis to increase the statistical power of our study
and to reduce motivation bias. In conclusion,
90
participants were
included in analyses involving the objective and subjective compre-
hension,
78
participants were included in all our analyses, including
those concerning the direct comparison and those involving the
participants’ privacy concerns or numeracy skills.
Consequently, we included
90
submissions in the analysis:
27
for
RISK
,
30
for
RRT
, and
33
for
DEF
. Of these participants,
66
indi-
cated a “STEM” study field of science, technology, engineering, or
mathematics (
28
were students of computer science/engineering).
Five students indicated a study field of management or economics,
eight students indicated a study field related to architecture or de-
sign, and
11
students indicated a study field of social sciences, or
psychology. The age of the participants ranged from
18
to
40
years
with a mean age of approximately
25.03
and a median age of
24
.
The level of education was high overall, with
73
participants having
a bachelor’s degree or higher. Of these,
13
participants stated that
they had a master’s degree. These
90
participants spent an average
of 34.8minutes on the study.
3.5 Data Set Pre-processing and Analysis
Each participant received a score for subjective comprehension
and an objective comprehension score, both between
0
and
1
corre-
sponding to “very poor” and “very good” comprehension, respec-
tively. To obtain the subjective comprehension score, we calculated
the mean score of the three subjective comprehension questions for
each participant. We thereby inverted the score of the first question
so that for every question a higher score indicated greater com-
prehension. We then normalized the scores to a range from
0
to
1.
To measure objective comprehension, we scored each correct and
incorrect answer as
1
and
0
, respectively. We calculated the mean
of the four objective comprehension questions for each participant
and normalized the objective score to be between 0and 1.
225
Loading more pages...