
Nghia Duong-Trung, Stefan Born, Jong Woo Kim, Marie-Therese
Schermeyer, Katharina Paulick, Maxim Borisyak, Mariano Nicolas
Cruz-Bournazou, Thorben Werner, Randolf Scholz, Lars
Schmidt-Thieme, Peter Neubauer, Ernesto Martinez
When bioprocess engineering meets machine
learning: A survey from the perspective of
automated bioprocess development
Open Access via institutional repository of Technische Universität Berlin
Document type
Journal article | Accepted version
(i. e. final author-created version that incorporates referee comments and is the version accepted for
publication; also known as: Author’s Accepted Manuscript (AAM), Final Draft, Postprint)
This version is available at
https://doi.org/10.14279/depositonce-17066
Citation details
Duong-Trung, N., Born, S., Kim, J. W., Schermeyer, M.-T., Paulick, K., Borisyak, M., Cruz-Bournazou, M. N.,
Werner, T., Scholz, R., Schmidt-Thieme, L., Neubauer, P., & Martinez, E. (2023). When bioprocess engineering
meets machine learning: A survey from the perspective of automated bioprocess development. In Biochemical
Engineering Journal (Vol. 190, p. 108764). Elsevier BV. https://doi.org/10.1016/j.bej.2022.108764.
Terms of use
This work is protected by copyright and/or related rights. You are free to use this work in any way permitted by
the copyright and related rights legislation that applies to your usage. For other uses, you must obtain
permission from the rights-holder(s).

When Bioprocess Engineering Meets Machine Learning:
A Survey from the Perspective of Automated
Bioprocess Development
Nghia Duong-Trunga,∗, Stefan Borna, Jong Woo Kima,d, Marie-Therese
Schermeyera, Katharina Paulicka, Maxim Borisyaka, Mariano Nicolas
Cruz-Bournazoua, Thorben Wernerb, Randolf Scholzb, Lars Schmidt-Thiemeb,
Peter Neubauera, Ernesto Martineza,c,∗
aTechnische Universit¨at Berlin, Faculty III Process Sciences, Institute of Biotechnology,
Chair of Bioprocess Engineering.
Straße des 17. Juni 135, 10623 Berlin, Germany.
bUniversity of Hildesheim, Information Systems and Machine Learning Lab (ISMLL).
Universit¨atspl. 1, 31141 Hildesheim, Germany.
cINGAR (CONICET-UTN), Avellaneda 3657, S3002GJC, Santa Fe, Argentina.
dDepartment of Energy and Chemical Engineering, Incheon National University, Incheon
22012, Republic of Korea.
Abstract
Machine learning (ML) is becoming increasingly crucial in many fields of en-
gineering but has not yet played out its full potential in bioprocess engineer-
ing. While experimentation has been accelerated by increasing levels of lab
automation, experimental planning and data modeling are still largerly depend
on human intervention. ML can be seen as a set of tools that contribute to
the automation of the whole experimental cycle, including model building and
practical planning, thus allowing human experts to focus on the more demand-
ing and overarching cognitive tasks. First, probabilistic programming is used
for the autonomous building of predictive models. Second, machine learning
automatically assesses alternative decisions by planning experiments to test hy-
potheses and conducting investigations to gather informative data that focus
on model selection based on the uncertainty of model predictions. This re-
view provides a comprehensive overview of ML-based automation in bioprocess
development. On the one hand, the biotech and bioengineering community
should be aware of the potential and, most importantly, the limitation of ex-
isting ML solutions for their application in biotechnology and biopharma. On
the other hand, it is essential to identify the missing links to enable the easy
implementation of ML and Artificial Intelligence (AI) tools in valuable solutions
for the bio-community. There is no one-fits-all procedure; however, this review
should help identify the potential for automating model building by combin-
ing first-principles biotechnology knowledge and ML methods to address the
∗Corresponding authors: Nghia Duong-Trung and Ernesto Martinez
Preprint submitted to Biochemical Engineering Journal
November 9,
2022

reproducibility crisis in bioprocess development.
Keywords: Active Learning, Automation, Bioprocess Development,
Reinforcement Learning, Reproducibility crisis.
1. Introduction
In the wake of climate change, many industries are turning to biotechnology
to find sustainable solutions. The importance of biotechnological processes in
pharmaceuticals is reflected in the growth figures for biopharmaceuticals (up
14 % to 30.8 % market share from 2020 to 2021)[1]. This trend is currently5
strongly inhibited by the long development times of biotechnological processes.
To advance fast in bioprocess development, decisions must be taken under con-
siderable high uncertainty, which does not enable a fast transition from labora-
tory to industrial production at scale with acceptable risks. Usually, different
microorganisms or cells are tested to produce an industrial-relevant product,10
i.e., a pharmaceutical substance. The transfer of results from small to large
scale represents a central challenge and is very time-consuming and error-prone.
Modern biolabs have automatized and parallelized many tasks aiming to run
such a large number of experiments in short periods. These Robotic experimen-
tal facilities are equipped with Liquid Handling Stations (LHS) [2, 3], parallel15
cultivation systems, and High Throughput (HT) [4, 5] analytical devices which
make them capable of timely generating informative data over a wide range of
operating conditions. The past decade’s focus was on hardware development
and device integration with relatively simple data management systems lacking
automatic association of the relevant metadata for the resulting experimental20
data. We have not been able to trigger the fruitful symbiosis expected between
(i) robots that can perform thousands of complex tasks but are currently wait-
ing for humans to design and operate the experiments; (ii) Active Learning
(AL) algorithms that still rely on humans to perform the planned experiments,
and (iii) Machine Learning (ML) tools are at the present waiting for humans to25
treat and deliver the data in a digital, machine-actionable format. Hence, end-
to-end digitalization of experiments is a prerequisite to applying ML methods
in bioprocessing.
Without complete annotations, the knowledge about how data were gener-
ated remains hidden, thus limiting the possible degree of automation for control30
and experimental design but also hampering the aggregation of data from differ-
ent contexts. More importantly, difficulties in reproducing experiments prevent
sharing and reuse by other researchers of costly experimental data.
Accordingly, with the advent of high-throughput robotic platforms, the bot-
tleneck to efficient experimentation on a micro-scale has thus shifted from run-35
ning a large number of parallel experiments to data management, model build-
ing, and experimental design, all of which currently rely on a considerable
amount of human intervention which makes experiments barely reproducible.
Only a proper data management system with standardized machine-actionable
2

data and automated metadata capture would allow an automatic flow of in-40
formation through all stages of experimentation in bioprocess development and
facilitate the use of machine learning models for decision-making in the face of
uncertainty.
Let us consider scale-up as a representative example of the importance of
metadata and experiment reproducibility. Miniaturized and versatile multi-45
bioreactor systems combined with LHS have the potential to significantly con-
tribute to the practical generation of informative data to increase scale-up effi-
ciency bearing in mind robustness to face the variability in operating conditions
during strain selection at the initial stage. When transferring the acquired
knowledge in the lab to the industrial scale, the remaining uncertainty in model50
predictions is significantly high due to insufficient data annotation and low levels
of automation. Hence, critical decisions must be taken under high uncertainty,
which imposes significant risks to most decisions taken throughout the biopro-
cess lifecycle.
The different stages of development cannot be treated in isolation. For55
example, the variability of operating conditions during strain selection directly
influences the reproducibility of productivity levels in the scaled process. Hence,
a promising route to faster development of innovative bioprocesses is a compre-
hensive automation of model building and experimental design across all stages
of development. To drastically speed up the bioprocess development of inno-60
vative products, the ubiquitous use of automation in active learning from data
and model building must be introduced in all stages, from product conceptual-
ization to reproducible end-use properties. At any of these development stages,
problem-solving and decision-making require building a model with enough pre-
dictive capability and a proper evaluation of its associated uncertainty.65
In today’s practice, model building and data collection depend heavily on
manual tweaking and human intervention, which slows down the development
effort and constitute a significant obstacle to lower costs and shorter times to
market. Also, ML algorithms should be deployed with higher levels of auton-
omy to release the end-user from choosing alternatives for algorithms, hyper-70
parameters, and problem representation incompatible with their understanding
of the methods involved and underlying assumptions.
This review follows two crucial aims. On the one hand, the biotech and bio-
engineering community should be aware of the potential and, most importantly,
some limitations of existing ML methods for their application in biotechnology75
and biopharma. On the other hand, it is essential to identify the missing links to
enable the easy implementation of ML and Artificial Intelligence (AI) solutions
in valuable solutions for the bio-community as end-users.
1.1. Decisions and Models
As shown in Fig. 1, model building is an important activity to assess alter-80
natives and advance fast in the bioprocess lifecycle by making rational decisions
that systematically reduce uncertainty. Model-based decision-making is widely
used in the development lifecycle of different processes and products (e.g., elec-
trical, chemical, aeronautics) for cost-effective design and improved operation
3
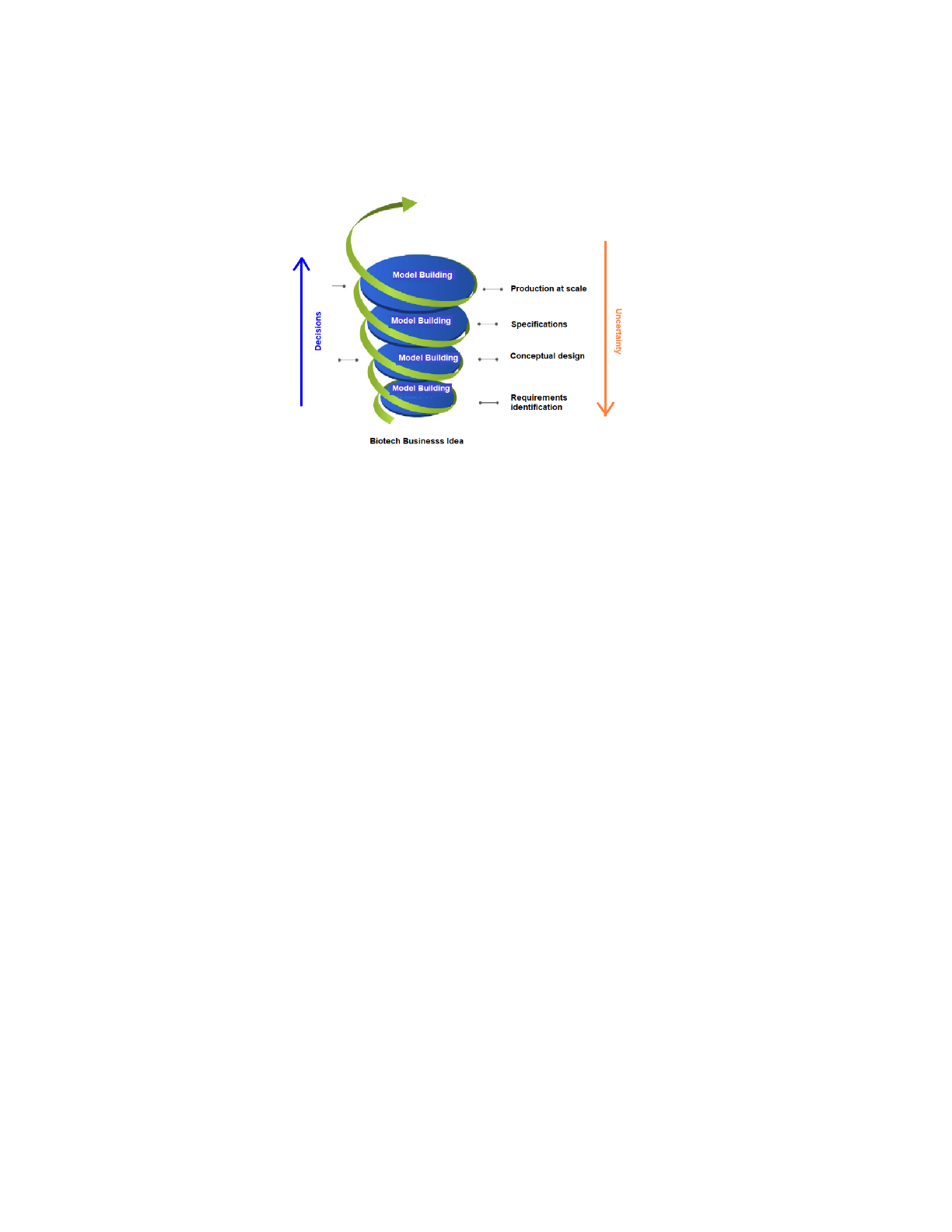
Figure 1: Reducing uncertainty in the bioprocess development lifecycle.
in the face of uncertainty. Mainly due to the so-called “small data problem,”85
[6] bioprocess development has been an exception, though, with a significantly
higher degree of empiric procedures, expert-based decisions, and strongly seg-
mented design strategies and strain screening methods. The increased complex-
ity of living organisms with thousands of intracellular biochemical reactions and
uncomprehended responses in their metabolic activity due to regulatory mech-90
anisms, combined with the difficulties in obtaining trustworthy observations,
make it very difficult to build sound mathematical models since data collected
from biological systems are inherently scarce and low-dimensional. However,
similar dynamic behaviors within families of genetically modified microorgan-
isms make enough room for transfer learning and meta-learning, using available95
data (with their metadata) to build predictive models for a new, unseen mutant.
Based on such prior knowledge, experiments can be readily designed to gather
informative data to increase the predictive power of models built to support
decision-making effectively.
1.2. Automated Model-Building100
Automation of the model-building cycle aims to assist experts and scientists
in facilitating and transforming decision-making in the context of bioprocess en-
gineering and biotechnology, not replacing them. Some model-building aspects
are more difficult to automate because of technological challenges and involve
open-ended questions and context-dependent tasks requiring human cognitive105
abilities. The most difficult challenge to model-building automation is that
data sources in the development pipeline are diverse, distributed, and multi-
structured. Moreover, not only the available data is highly heterogeneous, but
they also may need to be more informative regarding the purpose of the model
for a given stage. This fact contrasts sharply with the common assumption110
that sufficient amounts of high-quality data are available for model building.
4
Loading more pages...