
This version is available at https://doi.org/10.14279/depositonce-8185
© © 2019 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for
all other uses, in any current or future media, including reprinting/republishing this material for
advertising or promotional purposes, creating new collective works, for resale or redistribution to
servers or lists, or reuse of any copyrighted component of this work in other works.
Terms of Use
Lal, S.; Lucas, J.; Juurlink, B. (2019): SLC: Memory Access Granularity Aware Selective Lossy
Compression for GPUs. In: 2019 Design, Automation & Test in Europe Conference & Exhibition (DATE),
Narcg 25–29, 2019, Florence, Italy. IEEE.
Sohan Lal, Jan Lucas, Ben Juurlink
SLC: Memory Access Granularity Aware
Selective Lossy Compression for GPUs
Submitted manuscript (Preprint)Conference paper |
SLC: Memory Access Granularity Aware Selective
Lossy Compression for GPUs
Sohan Lal, Jan Lucas, Ben Juurlink
Technische Universität Berlin, Germany
{sohan.lal, j.lucas, b.juurlink}@tu-berlin.de
Abstract—Memory compression is a promising approach for
reducing memory bandwidth requirements and increasing per-
formance, however, memory compression techniques often result
in a low effective compression ratio due to large memory
access granularity (MAG) exhibited by GPUs. Our analysis of
the distribution of compressed blocks shows that a significant
percentage of blocks are compressed to a size that is only a few
bytes above a multiple of MAG, but a whole burst is fetched
from memory. These few extra bytes significantly reduce the
compression ratio and the performance gain that otherwise could
result from a higher raw compression ratio. To increase the
effective compression ratio, we propose a novel MAG aware
Selective Lossy Compression (SLC) technique for GPUs. The key
idea of SLC is that when lossless compression yields a compressed
size with few bytes above a multiple of MAG, we approximate
these extra bytes such that the compressed size is a multiple of
MAG. This way, SLC mostly retains the quality of a lossless
compression and occasionally trades small accuracy for higher
performance. We show a speedup of up to 35% normalized to a
state-of-the-art lossless compression technique with a low loss in
accuracy. Furthermore, average energy consumption and energy-
delay-product are reduced by 8.3% and 17.5%, respectively.
I. INTRODUCTION
Memory compression has been demonstrated as a promising
alternative to increase memory bandwidth [1]–[3], however,
memory compression techniques often exhibit a low effective
compression ratio. The main reason for the low effective
compression ratio is the large memory access granularity
(MAG) exhibited by GPUs due to wide bus width and large
burst length. For example, MAG of GDDR5/5X/6 is 32B
resulting from 32-bit bus width and 8 burst length. MAG is
the amount of data read from or written to a memory by a
single read or write command. MAG reduces the compression
ratio as data can only be fetched in a multiple of MAG but
a compressed block is often not a multiple of a MAG. For
example, for a compressed size of 36B, we fetch 64B. Thus,
a compression ratio that seems close to 4×(3.6×, assuming
a typical block size of 128B in current GPUs) is actually only
2×. This leads to a significant difference between the raw and
effective compression ratio actually gained by a system. The
raw compression ratio is calculated without considering MAG,
while the effective compression ratio is calculated by scaling
up the compressed size to the nearest multiple of a MAG.
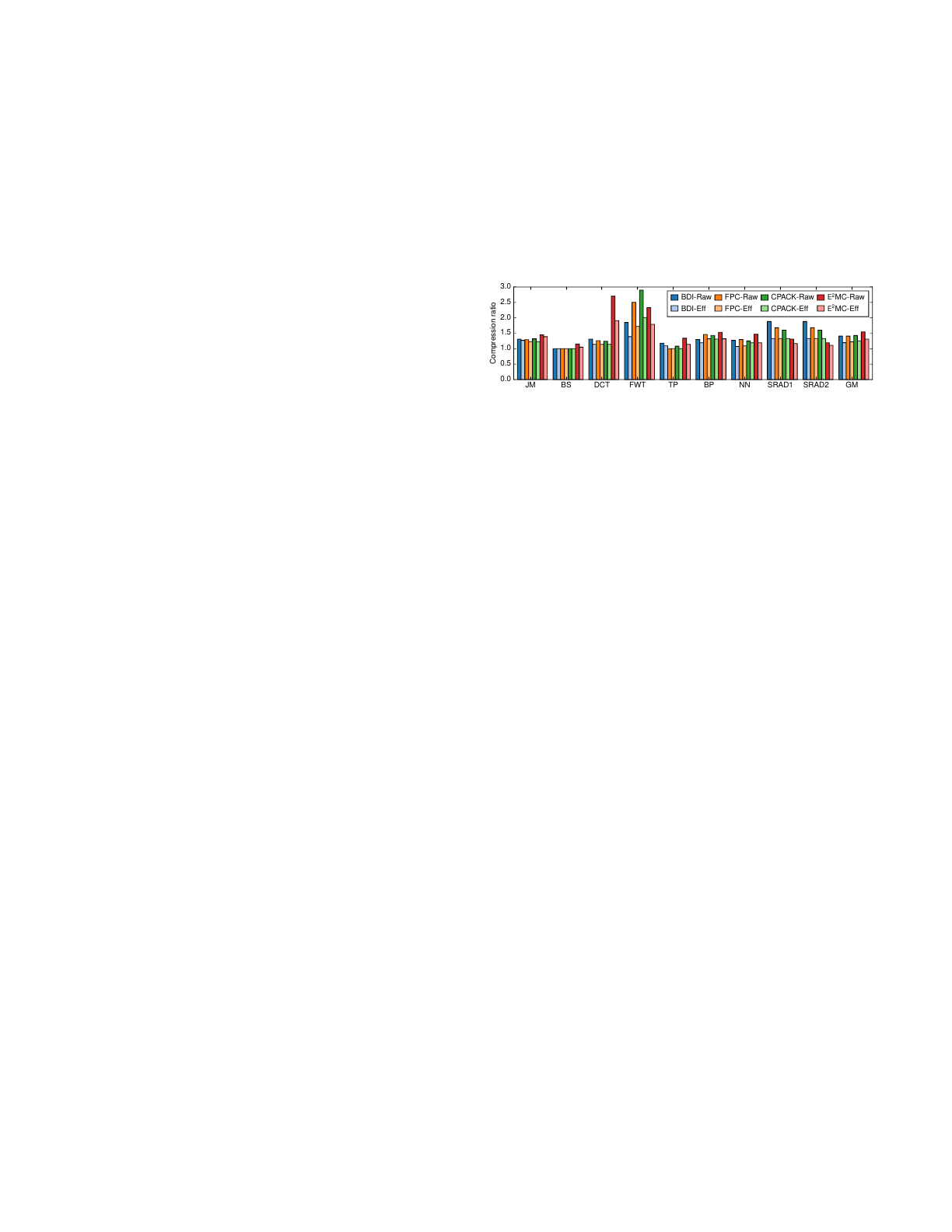
Figure 1 shows the raw and effective compression ratios
of BDI [4], FPC [5], C-PACK [1], and E2MC [3] techniques
This work has received funding from the European Union’s Horizon 2020
research and innovation programme under grant agreement number 688759.
JM BS DCT FWT TP BP NN SRAD1 SRAD2 GM
0.0
0.5
1.0
1.5
2.0
2.5
3.0
Compression ratio
BDI-Raw
BDI-Eff
FPC-Raw
FPC-Eff
CPACK-Raw
CPACK-Eff
E2MC-Raw
E2MC-Eff
Fig. 1: Raw and effective compression ratio of BDI, FPC, C-
PACK and E2MC using MAG of 32B.
for several memory-bound benchmarks. The geometric mean
(GM) of the effective compression ratio of BDI, FPC, C-PACK
and E2MC is 22%, 19%, 18%, and 23% less than the GM
of the raw compression ratio, respectively. The low effective
compression ratio reduces performance benefits, otherwise
possible from a higher raw compression ratio.
Interestingly, our study of the distribution of compressed
blocks (presented in Section II-B) shows that a significant per-
centage of compressed blocks have only a few bytes above a
multiple of MAG. With the goal to reduce the compressed size
by these extra bytes, we propose a novel MAG aware Selective
Lossy Compression (SLC) technique. The key idea of SLC is
that when a lossless compression yields a compressed size
with a few bytes above MAG, we use lossy compression to
approximate these few bytes such that the compressed size
is a multiple of MAG. This way, we selectively introduce a
small approximation error, however, we significantly increase
the compression ratio. Fortunately, there are several GPU
applications that are inherently resilient to small error [6], [7].
Considering that E2MC provides the highest compression
ratio, we choose E2MC as the baseline lossless compression
for SLC. However, SLC is not limited to E2MC but can also
be applied to other techniques. A key challenge of SLC is
to find the number of symbols needed to be approximated
to decrease the compressed size to a multiple of MAG. We
use a tree structure to select the required symbols and call this
technique as Tree-based SLC (TSLC). For a lossy threshold of
16B, SLC provides a speedup of up to 17% with < 1% average
error. In summary, we make the following contributions:
•We quantitatively show that low effective compression
ratio due to MAG exists in four state-of-the-art techniques
and qualitatively in three more.
•We propose a novel MAG aware Selective Lossy Com-
pression technique for GPUs. We show a significant
performance gain with a minimal loss in accuracy.
•This is the first study that highlights the importance of
MAG aware compression by quantitatively studying the
distribution of compressed blocks above MAG.
•We implement hardware and show the area and power
cost of SLC is only 0.0015% and 0.0008% of GTX580.
This paper is organized as follows. In Section II we further
motivate the problem. In Section III we present SLC in detail.
Section IV explains the experimental setup and results are
presented in Section V. Section VI describes related work and
finally, we draw conclusions in Section VII.
II. MOTIVATION
A. Qualitative Analysis of More Compression Techniques
Figure 1 quantitatively shows that four state-of-the-art mem-
ory compression techniques suffer due to MAG. There are
three other techniques: SC2[8], HyComp [9] and BPC [10]
that can also be applied for memory compression. SC2[8]
is a statistical cache compression technique and is similar to
E2MC [3] because both are based on Huffman encoding. The
former is proposed for CPUs, while the later is proposed for
GPUs. Therefore, SC2will suffer due to MAG. HyComp is a
hybrid compression method which improves the compression
ratio by selecting a suitable compression method based on
the specific data-type. HyComp will also suffer from MAG as
two (BDI and SC2) out of the four compression methods that
HyComp selectively uses are already shown to suffer. The third
method called FP-H divides a floating-point number into three
fields and then employs SC2, that means FP-H will also suffer.
BPC stands for bit plane compression that uses transformation
to increase the compressibility and then uses either run-length
or frequent pattern encoding to compress the transformed data.
While transformation increases compressibility, BPC will still
suffer from MAG as both the run length and frequent pattern
encodings exploit patterns similar to FPC and C-PACK which
are already shown to suffer in Figure 1. Therefore, several
memory compression techniques suffer from MAG.
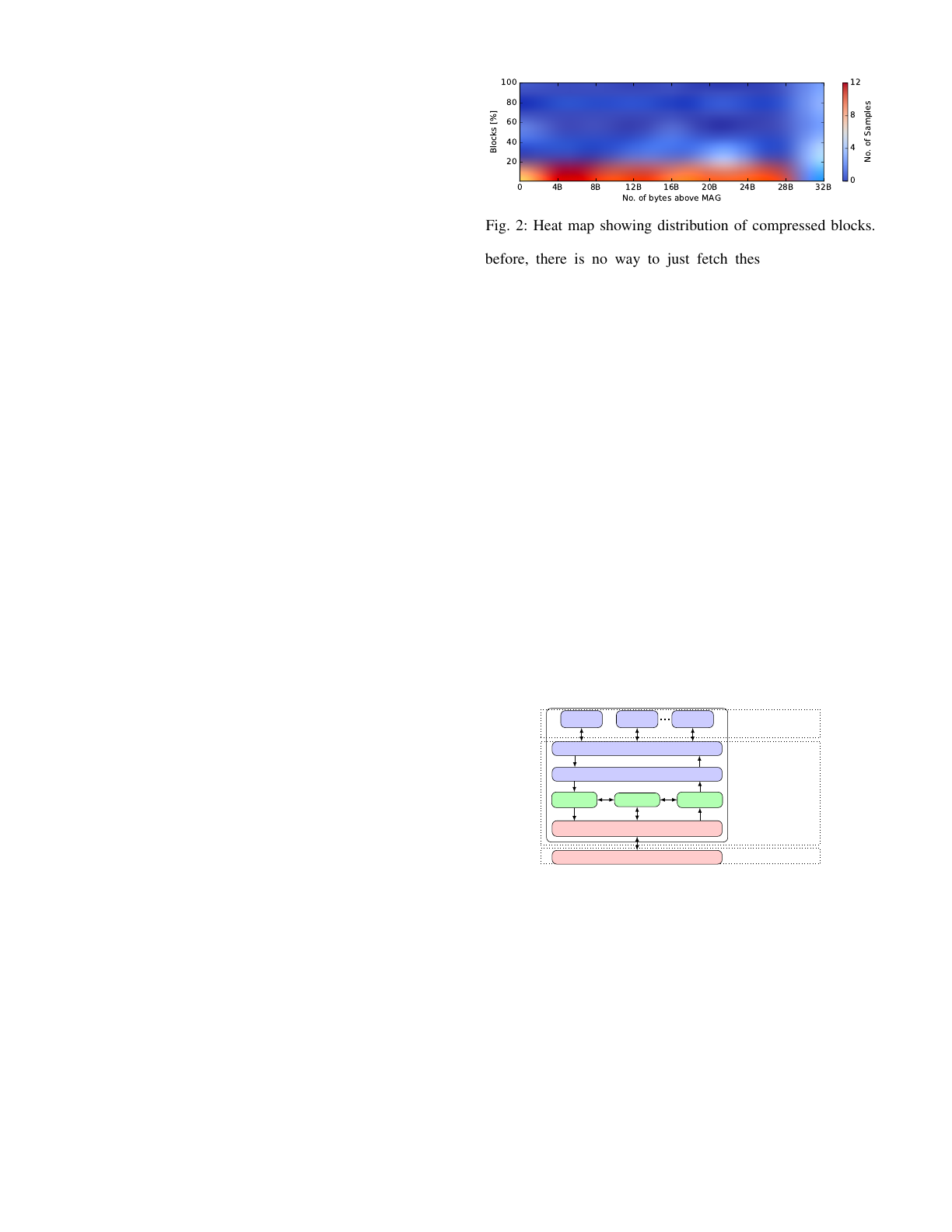
B. Distribution of Compressed Blocks at MAG
Figure 2 shows the heat map plot of the distribution of
compressed blocks at MAG using E2MC [3] for different
benchmarks (Details in Section IV-B). We assume a MAG
of 32B and a block size of 128B, which are typical values in
current GPUs. The x-axis shows the number of bytes above
a multiple of MAG. 0B on the x-axis means a compressed
block size is a multiple of MAG i.e. 32B, 64B, or 96B. For
simplification, all blocks with a compressed size <32B are
also included in the 0B origin. 32B on the x-axis represents the
percentage of uncompressed blocks. The left y-axis shows the
percentage of blocks and the right y-axis shows the number of
samples. The number of samples shows the number of times
a certain percentage of blocks e.g. 20% are compressed with
a certain number of bytes e.g. 4B above a multiple of MAG
for all benchmarks. Ideally, for a high effective compression
ratio, all blocks should be compressed to 0B above a multiple
of MAG. However, we see that there is a significant percentage
of blocks that are not compressed to an exact multiple of
MAG, but a few bytes above a multiple of MAG. As explained
0 4B 8B 12B 16B 20B 24B 28B 32B
No. of bytes above MAG
20
40
60
80
100
Blocks [%]
0
4
8
12
No. of Samples
Fig. 2: Heat map showing distribution of compressed blocks.
before, there is no way to just fetch these extra bytes, but
we have to fetch a whole 32B burst, causing a low effective
compression ratio. Nevertheless, these few extra bytes present
an opportunity to achieve a higher effective compression ratio
at low accuracy loss by selective approximation.
III. SELECTIVE LOSSY COMPRESSION
A. Overview of a System with SLC Components
Figure 3 shows an overview of a system with the main com-
ponents of SLC. The compressor, decompressor, and metadata
cache (MDC) are integrated into the memory controller (MC).
The memory controller needs to fetch only the required num-
ber of bursts for every compressed block to save bandwidth.
As the number of bursts varies from 1 to 4, we store 2 bits
in MDC similar to previous work [2], [3]. Data transfer to
and from DRAM is in compressed form with (de)compression
taking place in the MC. The data is stored in compressed
format in the DRAM, however, the goal is not to increase the
effective capacity but to increase the effective off-chip memory
bandwidth similar to [2], [3]. Hence, a compressed block is
still allocated the same size, although it may require less space.
Moreover, we decompress the required number of symbols to
recover the original block and the extra data that is fetched
due to MAG is meaningless and not interpreted.
Off-chip Memory
Memory Subsystem
Compute Subsystem
Comp MDC Decomp
Memory Controller
L2 Cache
Interconnection Network
DRAM
SM2
SM1SMn
Fig. 3: Overview of a system with compression components.
B. SLC Architecture
Figure 4 shows an overview of the SLC technique. Basically,
SLC is a budget-based compression technique which allows
selection between different compression modes depending
upon comp size,bit budget,extra bits, and a threshold. The
bit budget is a multiple of MAG i.e. 32B, 64B, 96B, or 128B.
When the comp size of a block is more than its uncompressed
size, the block is always stored uncompressed and the bit
budget is 128B. Since it is not possible to fetch less than
32B from memory, we also use lossless compression when
the comp size is less than 32B and in this case, the bit budget
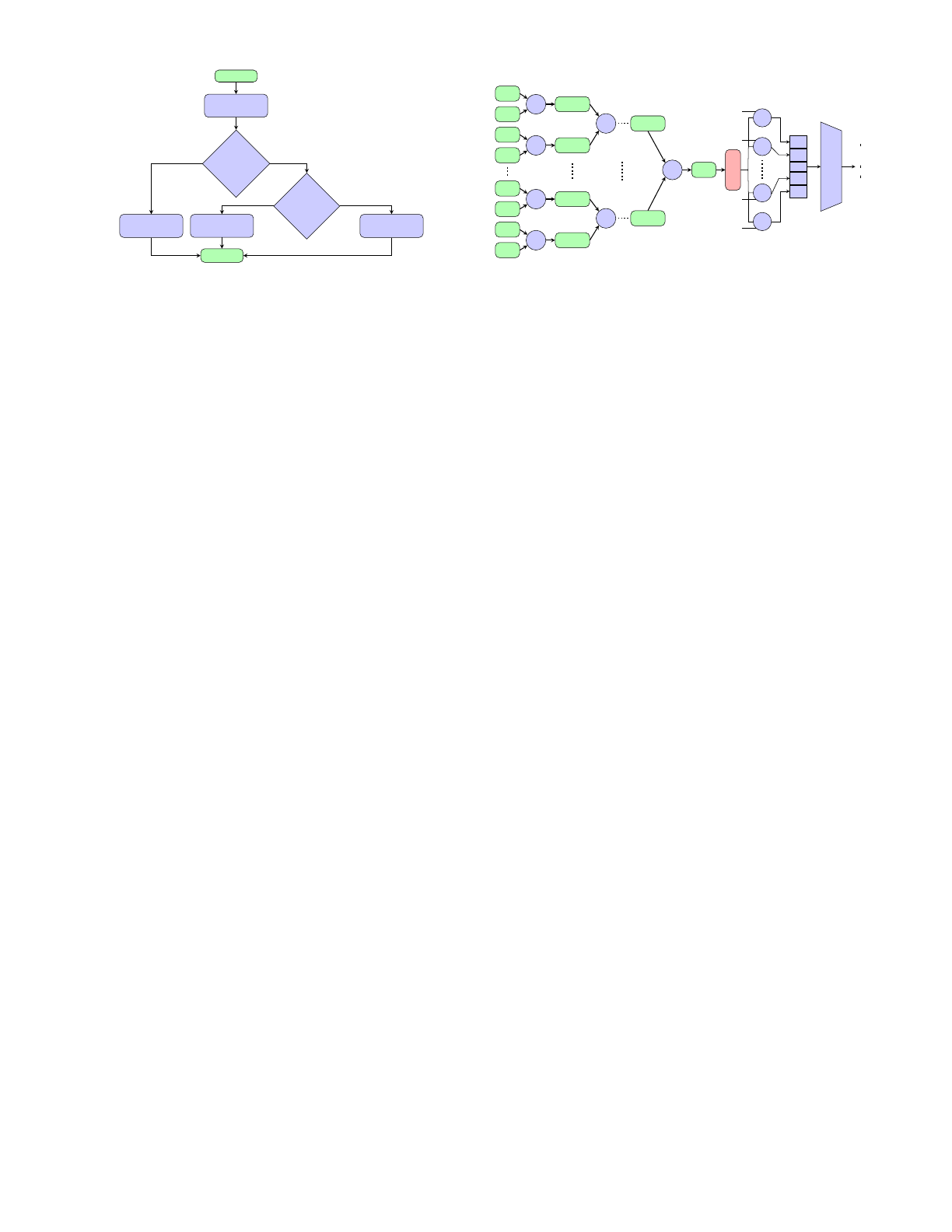
Start
Compute
Comp Size
Comp Size
==
Bit Budget
Use Lossless
Compression
Extra Bits
<=
Threshold
Use Lossy
Compression
Use Lossless
Compression
Stop
yes no
yes no
Fig. 4: Overview of selective lossy compression.
is also 32B. The extra bits are the number of bits above the
bit budget and the threshold is the number of bits defined by
a user that can be safely approximated.
Once we know the comp size, we check if it is equal
to bit budget. We use lossless compression when the comp
size is equal to bit budget. When the comp size is not equal
to bit budget, we use lossy compression if the extra bits
⩽threshold and lossless compression if the extra bits >
threshold. Thus, SLC mostly retains the quality of a lossless
compression and smartly trades small accuracy to achieve the
desired compression and higher performance.
We know how many bytes (extra bits) are above a MAG,
but the problem is that these extra bits are codewords and not
symbols. The challenge here is to find the number of symbols
that need to be approximated to decrease the compressed
size by extra bits. We determine the number of symbols
needed to be approximated using a tree structure and then
only approximate these symbols. We call this technique Tree-
based SLC (TSLC). We first describe how we compute comp
size,bit budget,extra bits, and threshold in Section III-C and
then explain TSLC in Section III-D.
C. Compressed Block Size, Bit Budget, and Extra Bits
To use SLC, the first thing that we require is the compressed
block size (comp size) that would result if only lossless
compression is used. However, we cannot wait for a lossless
compression to compress a block and then decide which
compression mode to use as compression incurs long latency.
Although GPUs can hide compression latency, too much
increase can also degrade their performance [3]. Fortunately,
we only need the comp size and not the compressed block to
choose a compression mode and the comp size can be easily
calculated by just adding all code lengths [3]. RTL synthesis
details to obtain the comp size are described in Section IV-A.
Once the comp size is known, bit budget of a block can
be computed. The bit budget is the closest multiple of MAG
⩽comp size. The possible values of bit budget are 32B,
64B, 96B, or 128B. The extra bits are simply calculated by
subtracting the bit budget from comp size.
D. Tree-based SLC
We use a parallel tree adder to add all code lengths of a
block and small additional logic to select the symbols for
approximation as shown in Figure 5. The last node of the
C1
C2
+C1,2
C3
C4
+C3,4
Cn-3
Cn-2
+Cn-3,n-2
Cn-1
Cn
+Cn-1,n
+C1..n-4
+Cn-3..n
+C1..n
extra bits
≥
≥
≥
≥
comp size
leveli[0]
leveli[1]
leveli[k-1]
leveli[k]
1
0
...
1
0
Sub-block Selector
sub block to approx
Level1Level2Leveln-1 LevelnComparator Stage Selection Stage
Fig. 5: Tree-based SLC.
tree contains the comp size that is used to find the bit budget
and extra bits. We use intermediate sums of the code lengths
to select the symbols for approximation as explained below.
When the lossy compression mode is selected, the extra bits
are compared with the intermediate sums at all levels in paral-
lel as shown in Figure 5. The output of comparisons is written
to a bit vector. It may happen that we do not find any sub-
block with compressed size (intermediate sum) ≥extra bits at
some levels. The output of the comparison stage is all zeros for
these levels. In the sub-block selection stage, priority encoders
are used to output the indices of the first sub-block with
compressed size ≥extra bits for each level of the tree. Finally,
a sub-block (sub_block_to_approx) with compressed size ≥
extra bits from the lowest level (approx_level) is selected
for approximation as at this level we need to approximate the
fewest symbols. As the sub_block_to_approx is selected in
parallel, the latency is fixed regardless of the approximated
level. The latency overhead is described in Section IV. Once
sub_block_to_approx is selected, the start symbol for approx-
imation is obtained by: sub_block_to_approx ×2approx_level.
E. Value Similarity-based Prediction
In TSLC, we simply truncate selected symbols during com-
pression that guarantees the desired compression, however,
truncation may cause a high error. Considering that we only
need to predict few symbols and adjacent threads in GPUs
have high-value similarity [6], [11], we decided to use a simple
value similarity-based prediction to reduce the error. While
decoding an approximated block, we use the value of the first
non-truncated symbol of the block as the predicted value for
truncated symbols. In terms of decompressor hardware change,
we only need to generate the index of the predicted value.
While there are exact value predictors [12], [13] with trade-
offs in terms of accuracy, complexity, and storage, we opt
for the very simple prediction scheme due to its negligible
hardware cost and reasonable accuracy for our use case.
F. TSLC Optimization
TSLC may approximate significantly more bits than needed
due to coarse intermediate sums at middle levels. This can
happen as a node at level l+1 has a sum of 2×the nodes at
level las shown in Figure 5 and when we cannot find a sub-
block with compressed size ≥extra bits at level l, we move to
l+1 and it may be the case that the largest sub-block at level

m ss len pdp Compressed data
Header
Fig. 6: Structure of a compressed block.
lis only a few bits less than the extra bits. The experiments
show that a significant unneeded approximation may happen at
the middle levels (3 and 4). The high unneeded approximation
does not happen at lower levels (<3) as the intermediate sums
are smaller and it also does not occur at higher levels (>4)
because we can mostly find a sub-block to approximate at
the middle levels. To reduce the unneeded approximation, we
further optimize TSLC by adding a few extra nodes at middle
levels. We add 8 and 4 extra nodes to have less coarse sums
at levels 3 and 4, respectively, which originally have 16 and
8 nodes. We can further optimize by having even fine-grained
sums, however, that will require more hardware resources.
G. Structure of a Compressed Block
Figure 6 shows the structure of a compressed block which
consists of a header and compressed data. The header is
needed to decompress a block. The header consists of 1-bit
(m) to indicate the compression mode (lossless or lossy), 6-bit
to store the index (ss) of the first approximated symbol, 4-bit to
store the number of approximated symbols (len), and 3 parallel
decoding pointers (pdp) for 4 parallel decoding ways (PDWs).
Experiments show that the maximum number of approximated
symbols is 16, thus we need 4-bit to store the len. Each pdp
consists of Nbits, where 2Nis the block size in bytes. No
header is needed for uncompressed block as in the baseline [3].
TABLE I: Frequency, area, and power of SLC.
Compressor Decompresor
Freq
(GHz)
Area
(mm2)
Power
(mW)
Freq
(GHz)
Area
(mm2)
Power
(mW)
1.43 0.00830 1.620 0.80 0.00030 0.210
H. Hardware Implementation and Overhead of SLC
To estimate the frequency, area and power overhead of SLC,
we wrote RTL and synthesized the design using Synopsis
design compiler version K-2015.06-SP4 at 32 nm node. Table I
shows the frequency and additional hardware overhead of
extending E2MC with TSLC. We only present synthesis results
for the optimized TSLC with prediction as the differences
are insignificant. The area and power overhead of TSLC is
only 0.0015% and 0.0008% of GTX580. Moreover, TSLC
only adds 5.6% of the area of E2MC. Therefore, in terms
of hardware overhead, SLC is feasible and very cheap.
IV. EXPERIMENTAL METHODOLOGY
A. Simulator
We modify gpgpu-sim [14] to integrate BDI, FPC, C-PACK,
E2MC, and SLC and configure it to simulate a GPU similar to
GTX580. Table II shows the configuration summary. For the
baseline lossless compression E2MC, we use 16-bit symbols,
4 PDWs and an online sampling size of 20 million instructions
as they provide the best results [3]. It takes 46 cycles to
compress and 20 cycles to decompress a block by E2MC. For
TABLE II: Baseline simulator configuration.
#SMs 16 L1 $ size/SM 16 KB
SM freq (MHz) 822 L2 $ size 768 KB
Max #Threads/SM 1536 #Registers/SM 32 K
Max CTA size 512 Shared memory/SM 48 KB
Memory type GDDR5 # Memory controllers 6
Memory clock 1002 MHz Memory bandwidth 192.4 GB/s
Bus width 32-bit Burst length 8
a block size of 128B and 16-bit symbols, a total of 64 code
lengths need to be read from the compressor table and added
to know the compressed block size. RTL synthesis shows
that all code lengths can be fetched in about 12 cycles at
1002 MHz and it requires another 2 cycles to add them and
select a sub-block for approximation. Thus, TSLC needs 60
cycles to compress a block. Due to very simple additional
decompression logic, a block in TSLC can be decompressed
in the same number of cycles as in E2MC. For estimating the
energy consumption, GPUSimPow [15] is modified with the
RTL synthesis based power models of E2MC and TSLC.
B. Benchmarks
We include memory-bound and amenable to approxima-
tion benchmarks shown in Table III. We use speedup and
application specific error metrics to trade-off performance and
accuracy in accord with [7], [11], [16]. We use mean relative
error (MRE) for applications which produce numeric outputs
and Normalized Root Mean Square Error (NRMSE) which
process images or belong to a signal processing domain. JM
finds the intersection between triangles and we use miss rate
to report the fraction of incorrect decisions.
TABLE III: Benchmarks used for experimental evaluation.
Name Short Description Input Error Metric #AR
JM Intersection of tri. [17] 400 K tri. pairs Miss rate 6
BS Options pricing [18] 4 M options MRE 4
DCT Discrete trans. [18] 1024×1024 img. Image diff. 2
FWT Fast walsh trans. [18] 8 M elements NRMSE 2
TP Matrix transpose [18] 1024×1024 NRMSE 2
BP Perceptron train. [19] 64 K elements MRE 6
NN Nearest neighbors [19] 20 M records MRE 2
SRAD1 Anisotropic diff. [19] 1024×1024 img. Image diff. 8
SRAD2 Anisotropic diff. [19] 1024×1024 img. Image diff. 6
C. Safe to Approximate Loads and Approximation Threshold
The research has shown that safety is a semantic property of
a program [20] and to identify a safe-to-approximate load or
region, it requires programming language support. Therefore,
it is a common practice that a programmer annotates the loads
or code regions [2], [11], [16]. Similar to previous work,
SLC also requires annotations, however, instead of burdening
a programmer with the task of identifying individual loads,
we opt for a model that is much easier to use and cheaper to
implement. In our model, a programmer specifies if a memory
region is safe to approximate using an extended cudaMalloc()
as shown below.
cudaMalloc(void** devPtr, size_t size,
bool safeToApprox, size_t threshold)
The address returned by the extended cudaMalloc() and size of
the memory allocation is used to determine if a load is safe to
approximate or not. We implement extended cudaMalloc() in
Loading more pages...